Kapitel 2: Task-Scheduling
Lernziele¶
Nach diesem Kapitel sollten Sie in der Lage sein:
den Unterschied zwischen statischem und dynamischem Scheduling zu erklären und geeignete Anwendungsfälle zu nennen.
die Begriffe Work (), Critical Path () und sequentielle Stapeltiefe () zu definieren und für ein gegebenes Programm zu bestimmen.
die Funktionsweise des Busy-Leaves-Algorithmus anhand seiner drei Regeln (Spawn, Stall, Die) zu erklären.
die Speicherschranke herzuleiten und zu interpretieren.
zu erklären, wie Work-Stealing die Idee des Busy-Leaves-Algorithmus dezentral umsetzt, warum das Opfer zufällig gewählt wird, und warum vom alten Ende der Deque gestohlen wird.
die Laufzeitschranke für den randomisierten Work-Stealing-Algorithmus zu nennen und einzuordnen.
reale Systeme zu nennen, die Work-Stealing implementieren (Cilk, Java ForkJoinPool, Intel TBB, OpenMP Tasks).
1. Einleitung und Definition¶
Scheduling bezeichnet im Kern die zeitliche Planung und Zuweisung von Aufgaben (Tasks) an verfügbare Ressourcen (Prozessoren). Während wir Scheduling aus vielen Bereichen der Informatik kennen (z. B. Prozess-Scheduling im Betriebssystem oder Job-Planung in Clustern), konzentriert sich das Task-Scheduling speziell auf die Planung von Teilaufgaben, die untereinander Abhängigkeiten aufweisen können.
Die zentrale Fragestellung¶
Parallele Tasks werden von parallelen Prozessoren ausgeführt. Der Scheduler muss entscheiden: Welcher Prozessor führt welchen Task zu welchem Zeitpunkt aus?
Ziele des Schedulings¶
Bei der Entwicklung eines Schedulers müssen zwei oft gegensätzliche Ziele optimiert werden:
Minimierung der Gesamtausführungszeit (MakeSpan): Das Programm soll so schnell wie möglich fertiggestellt werden.
Effizienter Speicherverbrauch: Die parallele Ausführung darf den Speicherbedarf nicht unkontrolliert vergrößern (z. B. durch das unnötige Duplizieren von Ressourcen für jeden Thread).
2. Klassifizierung: Statisch vs. Dynamisch¶
Je nachdem, wann die Entscheidungen getroffen werden, unterscheidet man zwei Ansätze:
| Merkmal | Statisches Scheduling | Dynamisches Scheduling |
|---|---|---|
| Zeitpunkt | VOR der Ausführung (Offline) | WÄHREND der Ausführung (Online) |
| Voraussetzungen | Kenntnisse über Laufzeiten, Kommunikation und Abhängigkeiten müssen vorliegen. | Die Zukunft des Programms (folgende Tasks) ist unbekannt. |
| Modellierung | Oft durch präzise Task-Graphen (DAGs). | Oft durch abstrakte Thread-Modelle (wie bei Blumofe und Leiserson). |
| Anwendung | Hochgradig reguläre Probleme, Echtzeitsysteme. | Unregelmäßige Algorithmen, unbekannte Eingabedaten. |
3. Grundlagen der Performance-Messung¶
Um die Qualität eines Schedulers (insbesondere im dynamischen Umfeld) zu bewerten, werden zwei theoretische Maße herangezogen:
Work (): Die Zeit, die für eine rein sequentielle Ausführung auf einem einzigen Prozessor benötigt wird. Sie entspricht der Summe aller Instruktionen.
Critical Path (): Die minimale Ausführungszeit, die selbst bei einer unendlichen Anzahl von Prozessoren nicht unterschritten werden kann (die längste Kette von Abhängigkeiten im Graphen).
Ein optimaler Greedy-Scheduler für Prozessoren garantiert eine Laufzeit von .
4. Grundlagen und der Busy-Leaves-Algorithmus¶
Beim dynamischen Task-Scheduling ist die Struktur des Programms (welche Tasks als Nächstes entstehen) zur Laufzeit nicht bekannt. Das Ziel eines Schedulers ist es, die Gesamtlaufzeit () zu minimieren und gleichzeitig den Speicherverbrauch effizient zu begrenzen. Die theoretische Basis hierfür bildet das Modell von Robert D. Blumofe und Charles E. Leiserson (JACM 1999).
4.1 Das Task-Modell nach Blumofe und Leiserson¶
Um parallele Berechnungen mathematisch zu erfassen, nutzen Blumofe und Leiserson ein spezifisches Modell für Multithreaded-Programme:
Threads und Instruktionen: Eine Berechnung besteht aus einer Menge von Threads. Jeder Thread ist eine Sequenz von Instruktionen.
DAG (Directed Acyclic Graph): Die Abhängigkeiten werden als Graph dargestellt. Knoten sind Instruktionen, Kanten sind Abhängigkeiten.
Spawning: Ein Thread kann einen neuen Kind-Thread erzeugen (spawn).
Voll-strikte Berechnungen (Fully Strict): Dies ist eine entscheidende Einschränkung für die Vorhersagbarkeit. Eine Berechnung ist voll-strikt, wenn alle Abhängigkeitskanten, die aus einem Unterbaum herausführen, ausschließlich zum direkten Eltern-Thread gehen.
4.2 Der Busy-Leaves-Algorithmus¶
Der Busy-Leaves-Algorithmus ist ein idealisierter, zentralisierter Algorithmus, der beweist, dass man parallele Berechnungen mit optimalem Speicherverbrauch ausführen kann.
Funktionsweise¶
Der Algorithmus verwaltet alle bereiten Threads in einem globalen Thread-Pool.
Blatt (Leaf): Ein Thread im Spawn-Baum, der aktuell keine aktiven Kinder hat.
Busy-Regel: Der Algorithmus stellt sicher, dass zu jedem Zeitpunkt alle Blätter des Spawn-Baumes “busy” sind (d.h. von einem Prozessor bearbeitet werden).
Die drei Regeln:
(1) Spawn: Wenn ein Prozessor einen neuen Kind-Thread erzeugt, wird der Eltern-Thread in den globalen Pool zurückgelegt. Der Prozessor arbeitet am Kind-Thread weiter. Der Kind-Thread ist jetzt das neue Blatt und ist sofort “busy”.
(2) Stall: Wenn ein Thread auf das Ergebnis eines Kindes warten muss, wird er in den Pool zurückgelegt (als blockiert markiert) und der Prozessor wird frei.
(3) Die: Wenn ein Thread endet, prüft der Prozessor, ob der Eltern-Thread dadurch zum Blatt wird (d.h. keine weiteren lebenden Kinder hat). Falls ja, holt er den Eltern-Thread aus dem Pool und arbeitet an ihm weiter.
Beispiel: Parallele Summe mit 2 Prozessoren¶
Betrachten wir die parallele Berechnung von sum(a, b, c, d, e, f g, h). Das Programm erzeugt 5 Tasks:
Task 1: sum =
Task 2
Tasl 3 a+b =
Task 4 c+d =
Task 5
Task 6 e+f =
Task 7 g+h =
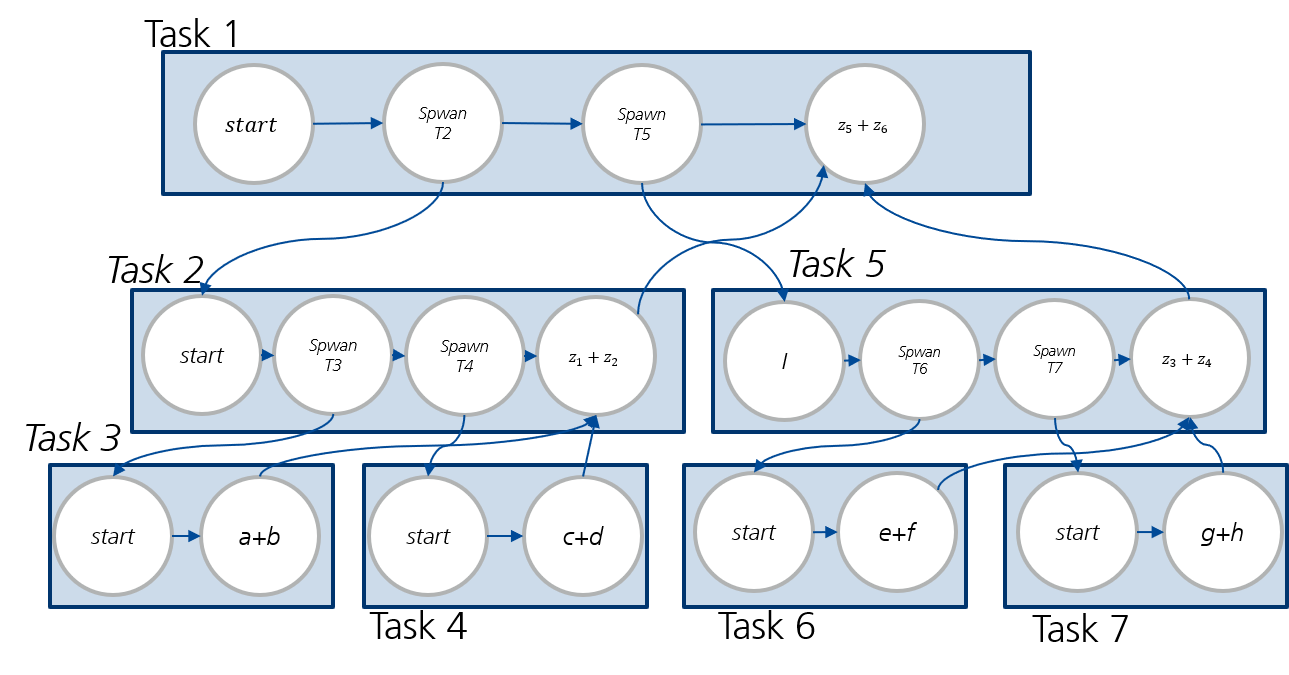
Figure 1:Möglicher Task-Graph für die Summenbildung
Ein möglicher TASK-Graph ist in Abblidung 1 dargestellt. Wir haben jeweils eine Einheit für den Start und eine für das Erzeugen eines Tasks.
Der Ablauf nach den Busy-Leaves-Regeln:
| Schritt | P1 | P2 | Queue |
|---|---|---|---|
| 1 | : Start | - | - |
| 2 | : Spwan | - | - |
| 3 | : Start | Spawn | - |
| 4 | : Spawan $T_3 | : Start | |
| 5 | : Start | :Spawn | , |
| 6 | : Start | , , | |
| 7 | : Spwan | , | |
| 8 | : Start | : Spawn | , |
| 9 | : Start | , , | |
| 10 | , | ||
| 11 | - | ||
| 12 | - | - |
Beobachtungen:
In Zeitschritt 3 legt P1 Task 1 in die Warteschlange, wo er direkt von P2 entnommen wird.
In Zeitschritt 4 wird Task 1 ebenfalls in die Queue gelegt, wo er jedoch blockiert.
In Zeitschritt 6/7 stirbt Task 3, sodass der Elterntask 2 keine lebenden Kinder mehr hat und von P1 übernommen wird.
Das Gleiche passiert in Zeitschritt 7/8 für P2 und Task 7 bzw. Task 5.
Im Zeitschritt 10/11 sind sowohl P1 als auch P2 „arbeitslos”, weil ihre Tasks beendet sind. Sie würden nun gleichzeitig auf die Queue zugreifen. In diesem Fall haben wir P2 den Elterntask T5 gegeben.
Etwas Ähnliches passiert im letzten Zeitschritt.
Das Problem der Skalierbarkeit¶
Der globale Task-Pool ist ein zentraler Flaschenhals: Alle Prozessoren konkurrieren um Zugriff auf denselben Pool. Bei vielen Prozessoren wird dies zum Engpass, weshalb Work-Stealing als dezentrale Umsetzung entwickelt wurde.
4.3 Speicher-Restriktionen (Space Bounds)¶
Die größte Stärke des Busy-Leaves-Ansatzes ist die Garantie über den Speicherplatzbedarf. In vielen parallelen Systemen kann der Speicherbedarf explodieren, wenn zu viele Threads gleichzeitig begonnen werden.
Blumofe und Leiserson beweisen für strikte Berechnungen: Die Menge an Speicher , die bei der Ausführung mit Prozessoren benötigt wird, ist begrenzt durch:
Definition (Sequentielle Stapeltiefe): ist der maximale Speicherbedarf bei rein sequentieller Ausführung auf einem Prozessor — im Wesentlichen die maximale Tiefe des Aufrufstapels multipliziert mit dem Speicher pro Stackframe. Bei rekursiven Programmen entspricht der maximalen Rekursionstiefe. Für
fib(n)wäre .
Warum ist das so?
Da wir nur Prozessoren haben, gibt es laut Busy-Leaves-Regel maximal aktive Blätter.
Jeder Thread, der Speicher belegt, ist entweder selbst ein Blatt oder ein Vorfahre eines Blattes.
Da die maximale Anzahl der Vorfahren durch die sequentielle Tiefe () begrenzt ist und es nur solcher Pfade gibt, skaliert der Speicherbedarf linear mit der Anzahl der Prozessoren.
Dies stellt sicher, dass ein Programm, das auf einem Rechner sequentiell läuft, auch auf einem parallelen System mit Prozessoren nicht am Speicher scheitert (vorausgesetzt, man hat -mal so viel Speicher zur Verfügung).
5. Herleitung: Work-Stealing (Praxis)¶
Der Busy-Leaves-Algorithmus ist theoretisch perfekt, benötigt aber einen zentralen Pool für freie Blätter, was bei vielen Prozessoren zum Flaschenhals wird. Work-Stealing ist die praktische, dezentrale Umsetzung dieser Idee.
5.1 Das Prinzip der Deque¶
Jeder Prozessor führt eine lokale Datenstruktur, eine Deque (Double-Ended Queue), in der bereite Threads gespeichert werden:
LIFO lokal (Stack-Prinzip): Ein Prozessor arbeitet lokal an seinen Tasks. Neue Tasls (durch Spawns) werden “oben” auf die Deque gelegt und sofort bearbeitet. Das entspricht der Busy-Leaves-Regel (das neueste Blatt wird sofort “busy”).
FIFO beim Stehlen (Queue-Prinzip): Läuft ein Prozessor leer, wird er zum Dieb. Er wählt ein Opfer-Prozessor gleichmäßig zufällig (uniform random) aus und stiehlt einen Task vom anderen Ende (unten) der Deque. Die Zufälligkeit ist kein Zufall: Die Laufzeitgarantie des Algorithmus basiert direkt darauf, dass kein deterministisch schlechtes Opfer gewählt werden kann.
Wird ein blockierter Task wieder Rechenbereit, kommt er in die Queue des Prozessors, der die Abhängigkeit aufgelöst hat.
Beispiel: Work-Stealing bei parallelem Fibonacci fib(4)¶
Eine Möglichkeit, Fibonacci zu berechnen, ist dies rekursiv zu tun;
int fib(int n) {
if (n < 2) return n;
int x = fib(n - 1);
int y = fib(n - 2);
return x + y;
}
Ein möglicher Task-Graph ist in Abbildung zu sehen.
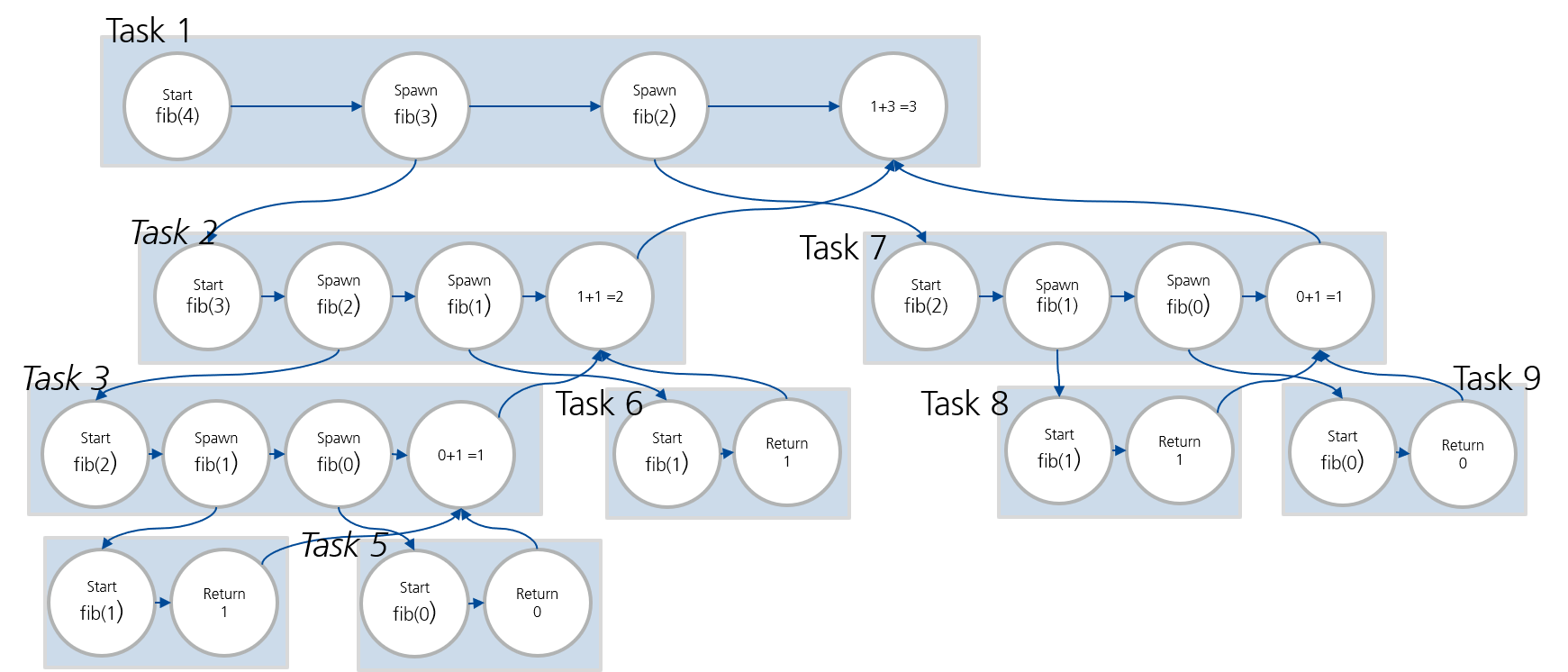
Figure 2:DAG für fib(4).
Es ergibt sich bei drei Prozessen, P1,P2 und P3 und einem Work-Stealing folgendes Bild:
| S | P1 | P2 | P3 | P1-Queue | P2-Queue | P2-Queue | Blocked |
|---|---|---|---|---|---|---|---|
| 1 | : start | - | - | - | - | - | |
| 2 | : spawn | - | - | - | - | ||
| 3 | : start | : spawn | - | - | - | - | |
| 4 | : spawn | : start | - | - | - | ||
| 5 | : start | : spawn | : spwan | - | - | ||
| 6 | spwan | start | : start | - | |||
| 7 | : start | : return 1 | : return 1 | - | |||
| 8 | : return 1 | : spawn | : spawn | - | - | - | |
| 9 | - | : start | start | - | - | - | |
| 10 | - | : return 0 | return 0 | - | |||
| 11 | - | - | - | ||||
| 12 | - | - | - | - | - | ||
| 13 | - | - | - | - | - | - |
Was dieses Beispiel zeigt:
In Schritt 3 stiehlt P2 von P1.
In Schritt 4 stiehlt P3 von P1.
In Schritt 8 stiehlt P3 erneut, diesemal von P1 aus der Queue.
In Schritt 9 ist kein Task rechenbereit, daher kann P1 keine Aufgaben erledigen.
In Schritt 10 beendet P3 , wodurch rechenbereit wird und in die Queue von P3 gelangt.
Genauso beendet P2 , wodurch rechenbereit wird und in der Queue von P2 landet.
Das Gleiche wiederholt sich in den nächsten Schritten für P3 und sowie .
5.2 Warum vom anderen Ende stehlen?¶
Das Stehlen vom “alten” Ende der Deque hat zwei entscheidende Vorteile:
Größere Arbeitspakete: Threads am unteren Ende der Deque sind meist “höher” im Aktivierungsbaum angesiedelt. Sie repräsentieren oft große Teilbäume. Ein Diebstahl bringt also viel Arbeit, was die Anzahl zukünftiger Diebstähle minimiert.
Konfliktvermeidung: Da der Besitzer oben arbeitet und der Dieb unten stiehlt, gibt es seltener Synchronisationskonflikte beim Zugriff auf die Deque.
5.3 Warum Work-Stealing statt Work-Sharing?¶
Work-Sharing: Versucht aktiv, Arbeit zu verteilen, auch wenn alle beschäftigt sind → Hoher Overhead durch häufige Synchronisation auf der gemeinsamen Queue.
Work-Stealing: Kommunikation findet nur dann statt, wenn ein Prozessor tatsächlich untätig ist. In einem gut ausgelasteten System gibt es fast keine Kommunikation.
Work-Stealing erfüllt die Busy-Leaves-Eigenschaft und ist ein Greedy-Algorithmus: Kein Prozessor bleibt unnötig idle, solange noch Arbeit vorhanden ist. Durch die verteilten Deques (eine pro Prozessor statt einer gemeinsamen Queue) müssen Threads nicht gleichzeitig auf eine gemeinsame Datenstruktur zugreifen — kein globales Locking, keine globale kritische Region. Die Performance ist dadurch in der Regel deutlich besser als beim Work-Sharing.
Inzwischen gibt es viele Optimierungen über den ursprünglichen Algorithmus hinaus:
Hierarchisches / lokalitäts-optimiertes Stehlen: Bevorzuge Opfer auf demselben NUMA-Knoten oder CPU-Sockel, um Cache-Kohärenz-Kosten zu senken.
Alternative Opfer-Metriken: Statt rein zufälliger Wahl können Auslastungsinformationen (Queue-Länge, CPU-Last) die Opferwahl verbessern.
5.4 Laufzeitgarantie des randomisierten Work-Stealing¶
Das zentrale Ergebnis von Blumofe und Leiserson: Der randomisierte Work-Stealing-Algorithmus erzielt für voll-strikte Berechnungen eine erwartete Laufzeit von:
Das bedeutet: Work-Stealing erreicht linearen Speedup — es wird praktisch so schnell wie theoretisch maximal möglich. Der Erwartungswert ist über die Zufälligkeit der Opferwahl, nicht über die Eingabe. Mit hoher Wahrscheinlichkeit weicht die tatsächliche Laufzeit kaum vom Erwartungswert ab.
Warum nur für voll-strikte Berechnungen? Der Beweis nutzt die Struktur der Deque aus (Lemma 4 im Paper): In einer voll-strikten Berechnung ist die Deque jedes Prozessors immer ein aufsteigender Pfad im Spawn-Baum (jeder Eintrag ist Elternteil des darunter liegenden). Dieses strukturelle Invariant bricht für allgemeinere Berechnungen.
6. Praxisbezug: Work-Stealing in realen Systemen¶
Die theoretischen Ergebnisse von Blumofe und Leiserson sind direkt in realen Parallelisierungsframeworks umgesetzt worden:
| System | Sprache | Besonderheit |
|---|---|---|
| Cilk / Cilk Plus | C/C++ | Direkte Implementierung des Papers; Schlüsselwörter cilk_spawn, cilk_sync |
| Java ForkJoinPool | Java | Standardbibliothek seit Java 7; Grundlage für parallele Streams |
| Intel TBB | C++ | task_group, parallel_for — Work-Stealing-basiert |
| OpenMP Tasks | C/C++/Fortran | #pragma omp task + #pragma omp taskwait |
Gemeinsames Muster: Alle diese Systeme erlauben es, Berechnungen rekursiv in kleinere Tasks zu zerlegen (spawn/fork), auf Ergebnisse zu warten (sync/join), und überlassen das Scheduling vollständig dem Laufzeitsystem.
Beispiel in Cilk (paralleles Fibonacci):
int fib(int n) {
if (n < 2) return n;
int x = cilk_spawn fib(n - 1); // spawn: Elternthread in Deque, weiter mit fib(n-1)
int y = fib(n - 2); // läuft inline
cilk_sync; // stall: warte auf gespawnten Thread
return x + y;
}Der Scheduler entscheidet zur Laufzeit, welche fib-Aufrufe parallel ausgeführt werden — ohne dass der Programmierer Threads manuell verwalten muss.
Ausblick auf die nächste Einheit: In der folgenden Einheit wird OpenMP Tasks vorgestellt — die in der Praxis am weitesten verbreitete Umsetzung dieser Idee. Genau das obige Fibonacci-Beispiel wird dort mit
#pragma omp taskund#pragma omp taskwaitimplementiert. Die theoretischen Konzepte aus diesem Kapitel (Spawn, Stall, Work-Stealing-Deque) sind dann direkt auf die OpenMP-Schlüsselwörter abbildbar.
Zusammenfassung¶
Das Modell von Blumofe und Leiserson zeigt, dass durch die konsequente Bearbeitung von Blättern (Busy-Leaves) die Speicherkomplexität im Griff bleibt. Das Work-Stealing übersetzt dies in ein hocheffizientes, dezentrales System, das die Kommunikation minimiert und die Lokalität maximiert.
Teil 2: Statisches Task-Scheduling (Heuristiken)¶
2.1 Modellierung mit Kommunikationskosten¶
Im statischen Scheduling sind alle Parameter vorab bekannt.
Knoten: Repräsentieren Tasks mit fixer Berechnungskosten .
Kanten: Repräsentieren Abhängigkeiten mit Kommunikationskosten .
Wichtige Regel: Kommunikation fällt nur an, wenn Task und Task auf verschiedenen Prozessoren ausgeführt werden. Läuft der Nachfolger auf dem gleichen Prozessor, sind die Kosten 0.
Zielgröße: Schedule Length = maximaler Fertigstellungszeitpunkt über alle Prozessoren. Minimierung von ist NP-vollständig.
CCR (Communication-to-Computation Ratio): Verhältnis der durchschnittlichen Kommunikationskosten zu den Berechnungskosten. Ein hoher CCR (z.B. 10) bedeutet kommunikationsdominante Workloads; ein niedriger CCR (z.B. 0.1) bedeutet berechnungsdominante Workloads. Der CCR beeinflusst stark, welcher Algorithmus die besten Ergebnisse liefert.
2.2 Prioritätszuweisung: t-level und b-level¶
Viele Heuristiken basieren auf zwei zentralen Attributen, die den “Rang” eines Tasks im DAG beschreiben:
t-level (top level): Die Länge des längsten Pfades vom Eingangsknoten bis zu (inkl. Kommunikationskosten). Beschreibt, wie früh ein Task frühestens starten kann.
b-level (bottom level): Die Länge des längsten Pfades von bis zum Ausgangsknoten (inkl. Knotengewicht und Kommunikationskosten). Beschreibt, wie kritisch ein Task für die Gesamtlaufzeit ist.
Static Level (SL): Wie b-level, aber ohne Kantenkostengewichte. Leicht berechenbar, ignoriert jedoch Kommunikationseffekte.
2.3 List-Scheduling-Heuristiken (BNP-Klasse)¶
Da das optimale statische Scheduling NP-hart ist, nutzen wir Heuristiken, um bereite Tasks aus einer Prioritätsliste zuzuweisen. Die folgenden Algorithmen gehören zur BNP-Klasse (Bounded Number of Processors — feste Prozessorzahl vorgegeben). Wir betrachten im folgenden den in Abbildung 3 dargestellten Graphen.
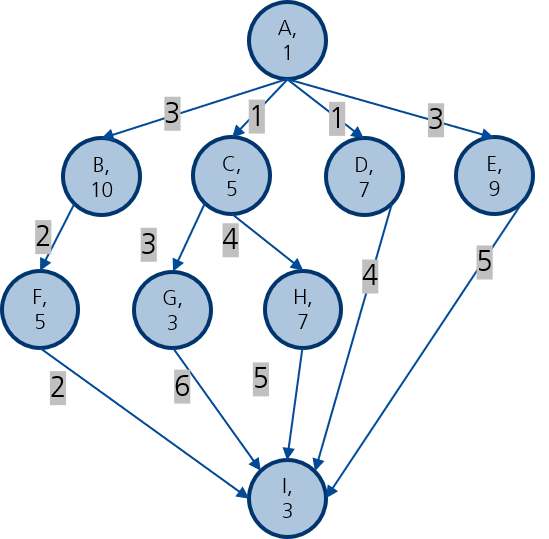
Figure 3:Beispiel DAG.
Für diesen Graphen ergibt sich:
| Knoten | b-Level | t-Level | static-level | ALAP |
|---|---|---|---|---|
| A | 26 | 0 | 19 | 0 |
| B | 21 | 4 | 18 | 5 |
| C | 24 | 2 | 15 | 2 |
| D | 14 | 2 | 10 | 12 |
| E | 17 | 4 | 12 | 9 |
| F | 10 | 15 | 8 | 16 |
| G | 12 | 10 | 6 | 14 |
| H | 15 | 11 | 10 | 11 |
| I | 3 | 23 | 3 | 23 |
A. HLFET (Highest Level First with Estimated Times)¶
Berechne für jeden Knoten das Static Level (SL): der längste Pfad vom Knoten bis zum Ausgangsknoten, nur mit Rechenzeiten, ohne Kantenkosten.
Priorisiere Tasks mit dem höchsten SL.
Weise jeden bereiten Task dem Prozessor zu, auf dem er am frühesten starten kann.
Vorteil: Einfach und schnell — statische Prioritätsliste wird einmalig berechnet.
Nachteil: Ignoriert Kommunikationskosten bei der Prioritätsvergabe vollständig.
Für den HLFET-Scheduler ergibt sich der in Abbildung dargestellte Schedule-
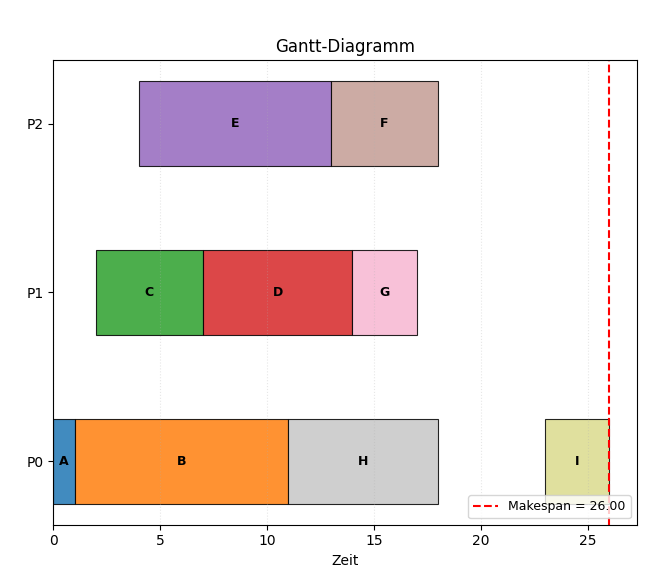
Figure 4:Ablauf für den HLFET-Algorithmus für den in Abbildung 3 dargestellten Task-Graphen.
B. ISH (Insertion Scheduling Heuristic)¶
Berechne das b-level (inkl. Kommunikationskosten) zur Prioritätsvergabe.
Weise den nächsten Task zunächst dem Prozessor mit der frühesten Startzeit zu.
Insertion-Schritt: Prüfe, ob der Task in eine Leerstelle (idle slot) eines anderen Prozessors eingefügt werden kann, ohne dessen nachfolgende Tasks zu verzögern — falls ja, bevorzuge diese Lösung.
Besonderheit: Die Einfüge-Strategie nutzt Leerzeiten gezielt aus und vermeidet so unnötige Verzögerungen.
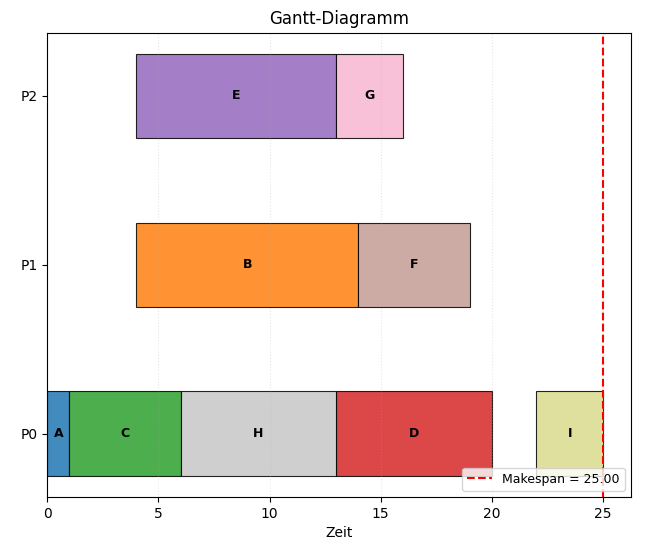
Figure 5:Ablauf für den ISH-Algorithmus für den in Abbildung 3 dargestellten Task-Graphen.
C. MCP (Modified Critical Path)¶
Berechne die ALAP-Zeit (As Late As Possible) für jeden Knoten: der spätestmögliche Startzeitpunkt, zu dem der Knoten noch ohne Verlängerung des Gesamtplans beginnen darf.
Erzeuge für jeden Knoten eine Liste aller ALAP-Zeiten auf dem Pfad vom Knoten zum Ausgangsknoten.
Priorisiere Tasks lexikographisch aufsteigend nach dieser Liste (die “dringendsten” Tasks zuerst).
Weise jeden Task dem Prozessor zu, auf dem er am frühesten starten kann.
Fokus: Minimierung der Verzögerung des kritischen Pfads durch ALAP-basierte Dringlichkeit.
Hinweis: Die korrekte Bezeichnung ist ALAP, nicht “ALST”. Die Listenbildung (nicht nur der Einzelwert) ist entscheidend für die Korrektheit des Algorithmus.
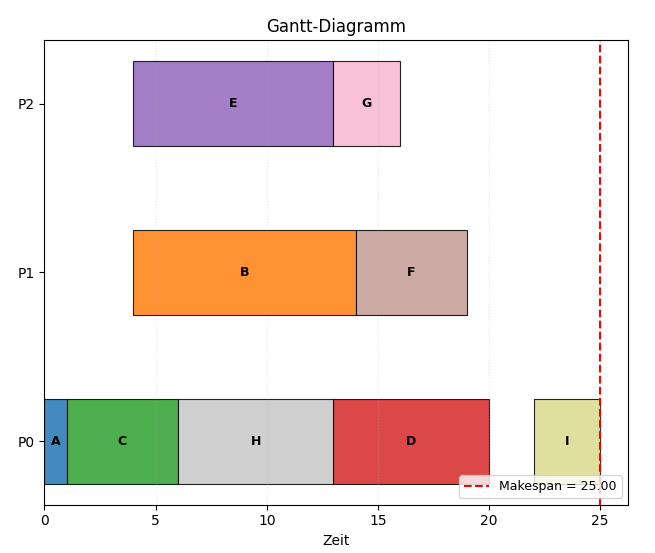
Figure 6:Ablauf für den MCP-Algorithmus für den in Abbildung 3 dargestellten Task-Graphen.
D. ETF (Earliest Time First)¶
Berechne für jeden bereiten Task auf jedem verfügbaren Prozessor die frühestmögliche Startzeit (EST).
Die EST berücksichtigt sowohl, wann der Prozessor frei ist, als auch, wann die Daten der Vorgänger (inkl. Kommunikation) eintreffen.
Wähle das Paar (Task, Prozessor) mit dem global kleinsten EST-Wert.
Fokus: Gierige, global-optimale Auslastung unter Einbeziehung der tatsächlichen Netzwerkkosten.
Nachteil: Höherer Berechnungsaufwand, da in jedem Schritt alle (Task, Prozessor)-Paare neu evaluiert werden.
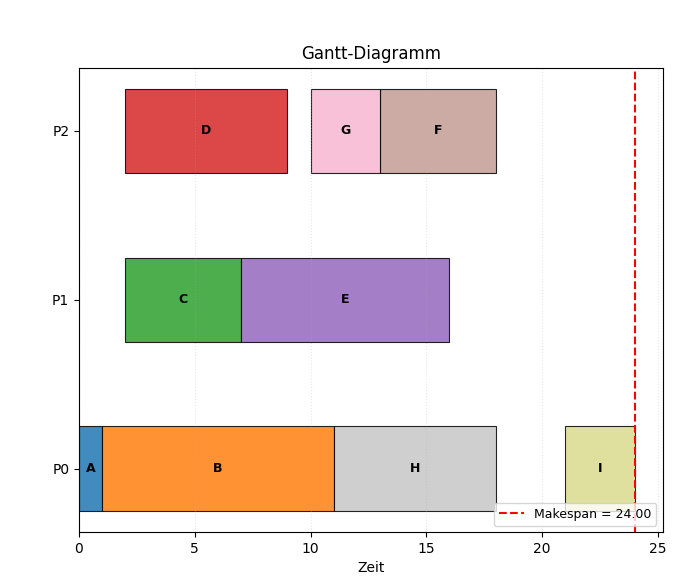
Figure 7:Ablauf für den ETF-Algorithmus für den in Abbildung 3 dargestellten Task-Graphen.
2.4 Empirischer Vergleich (Kwok & Ahmad, 1999)¶
Das Paper von Kwok und Ahmad vergleicht alle BNP-Algorithmen systematisch auf verschiedenen Benchmark-Graphen mit CCR .
Ranking nach Scheduling-Qualität (BNP-Klasse):
| Rang | Algorithmus | Stärke |
|---|---|---|
| 1 | MCP | Beste Gesamtperformance durch ALAP-Listenprioritäten |
| 2 | ISH | Effektive Ausnutzung von Idle-Slots |
| 3 | DLS | Gute dynamische Anpassung |
| 4 | HLFET | Einfach, aber ignoriert Kommunikation |
| 5 | ETF | Gute Qualität, aber hoher Rechenaufwand |
| 6 | LAST | Schlechteste Performance |
Zentrale Erkenntnisse:
Kritischer-Pfad-basierte Algorithmen (MCP, DLS) schlagen nicht-kritische-Pfad-Algorithmen durchgehend.
Dynamische Prioritätsvergabe (DLS, ETF) ist in der Regel besser als statische — Ausnahme: MCP, das trotz statischer Prioritätsliste die beste Gesamtperformance zeigt.
Der CCR beeinflusst die relative Performance stark: Bei kommunikationslastigen Workloads (hoher CCR) sind Algorithmen, die Kommunikationskosten einbeziehen (ETF, DLS), im Vorteil.
2.5 Zusammenfassung¶
Dynamisches Scheduling (Blumofe): Ideal für unbekannte Arbeitslasten. Fokus auf Speicherplatzgarantie und Dezentralität (Work-Stealing).
Statisches Scheduling: Ideal für reguläre Probleme (z.B. Signalverarbeitung). Fokus auf Minimierung der Kommunikationskosten durch Vorab-Analyse des DAG.
Algorithmuswahl: Für die meisten Szenarien liefert MCP die besten Ergebnisse in der BNP-Klasse; ETF und DLS sind bei kommunikationslastigen Graphen konkurrenzfähig.