Kurseinheit 5: Einführung in das GPU-Computing mit CUDA
Lernziele¶
Nach diesem Kapitel sollten Sie in der Lage sein:
den grundlegenden Architektur-Unterschied zwischen CPUs (Latenz-optimiert) und GPUs (Durchsatz-optimiert) zu erklären.
den Aufbau einer modernen GPU (SM, SP, Warp, Grid, Block) zu beschreiben.
ein einfaches CUDA-Programm zu schreiben: Kernel deklarieren, Thread-Indizes berechnen, Speicher verwalten, Kernel starten.
die Funktionsqualifizierer
__global__,__device__und__host__korrekt einzusetzen.das Konzept von Warps, Branch-Divergenz und Occupancy zu erklären und deren Auswirkungen auf die Performance zu benennen.
Memory Coalescing zu erklären und CUDA-Code danach zu beurteilen.
CUDA-Fehlerbehandlung korrekt anzuwenden (
cudaGetLastError,cudaDeviceSynchronize).1D- und 2D-Faltung auf der GPU zu implementieren und Randbehandlung (Ghost-Elements) korrekt umzusetzen.
1. CPU vs. GPU: Zwei unterschiedliche Designphilosophien¶
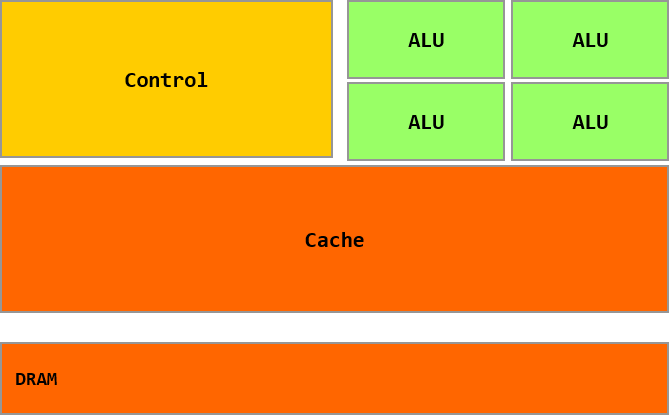
Figure 1:Aufbau einer CPU
CPU – Optimiert für geringe Latenz¶
CPUs sind darauf ausgelegt, einzelne Aufgaben so schnell wie möglich abzuarbeiten:
Starke ALU, optimiert auf minimale Latenz pro Operation.
Große, mehrlagige Caches (L1/L2/L3), um Hauptspeicherzugriffe zu verbergen.
Komplexe Kontrolllogik:
Branch Prediction: Vorhersage von Sprüngen zur Vermeidung von Pipeline-Blasen.
Out-of-Order Execution: Befehle werden intern umgeordnet, um Abhängigkeiten zu überbrücken.
Operand Forwarding: Vermeidet Verzögerungen in der Befehls-Pipeline.
GPU – Optimiert für hohen Durchsatz¶

Figure 2:Aufbau einer GPU
GPUs sind darauf ausgelegt, sehr viele einfache Aufgaben gleichzeitig abzuarbeiten:
Kleine Caches – Speicherlatenzen werden durch massives Pipelining und Thread-Switching versteckt, nicht vermieden.
Einfache Kontrolllogik: keine Branch-Prediction, kein Operand-Forwarding.
Kleine, energieeffiziente ALUs mit vergleichsweise hoher Einzellatenz – der Durchsatz entsteht durch Tausende parallele Einheiten.
Konsequenz: Beides zusammen nutzen¶
| Aufgabe | Besser auf |
|---|---|
| Sequentieller Code mit vielen Abhängigkeiten | CPU (>10× schneller als GPU) |
| Massiv-paralleler, datenunabhängiger Code | GPU |
Das typische CUDA-Programm läuft auf beiden: Die CPU (Host) steuert das Programm und führt sequentielle Teile aus; die GPU (Device) übernimmt die rechenintensiven, parallelen Abschnitte.
2. GPU-Architektur (Beispiel: NVIDIA Ampere)¶
Streaming Multiprozessor (SM)¶
Die grundlegende Recheneinheit der GPU ist der Streaming Multiprozessor (SM). Ein SM enthält:
4 Streaming Prozessoren (SP) (auch CUDA-Cores genannt)
L1-Instruktionscache
192 kB L1-Datencache / Shared Memory (konfigurierbar)
Ein einzelner SP enthält:
16 × 32-bit Integer-Einheiten (INT32)
16 × 32-bit Floating-Point-Einheiten (FP32)
8 × 64-bit Floating-Point-Einheiten (FP64)
Tensor Cores (für Matrix-Multiplikationen / KI)
GPU-Gesamtstruktur (Ampere A100)¶
Die SMs sind hierarchisch gruppiert:
2 SMs → 1 Texture Processor Cluster (TPC)
8 TPCs → 1 GPU Processing Cluster (GPC)
8 GPCs → 1 GPU (= 128 SMs gesamt)Weitere Merkmale der Ampere-Architektur:
PCIe 4.0 zur Anbindung an die CPU.
12 NVLink-Ports: bis zu 300 GB/s GPU-zu-GPU-Bandbreite.
12 HBM-Speicherbänke: bis zu 1.555 GB/s Speicherbandbreite.
Gemeinsamer L2-Cache für alle SMs.
3. Das CUDA-Programmiermodell¶
PTX – Die Intermediate Representation¶
CPUs und GPUs verwenden unterschiedliche Instruction Set Architectures (ISAs). CUDA-Code wird nicht direkt in GPU-Maschinencode übersetzt, sondern in PTX (Parallel Thread Execution) – eine GPU-ISA auf Zwischenebene. Der Grafiktreiber enthält einen JIT-Compiler, der PTX zur Laufzeit in ausführbaren Binärcode für die konkrete GPU-Generation übersetzt.
// PTX-Beispiel:
shr.u64 %rd14, %rd12, 32; // unsigned 64-bit right shift um 32 Stellen
cvt.u64.u32 %rd142, %r112; // unsigned 32-bit → 64-bit KonvertierungKernel – Eine Funktion für alle Threads¶
Ein CUDA-Kernel ist eine Funktion, die von der GPU ausgeführt wird. Alle Threads führen denselben Code aus (SIMD-Prinzip), unterscheiden sich aber durch ihre Indizes – und damit durch die Daten, auf die sie zugreifen.
Funktionsqualifizierer¶
| Qualifizierer | Ausgeführt auf | Aufrufbar von | Anmerkung |
|---|---|---|---|
__global__ | GPU | Host (CPU) | Kernel-Einstiegspunkt; Rückgabetyp muss void sein |
__device__ | GPU | GPU | Hilfsfunktion auf der GPU |
__host__ | CPU | CPU | Normaler C-Code; optional, da Standard |
__device__ __host__ | Beide | Beide | Wird für beide Seiten kompiliert |
Kompilierung mit NVCC¶
C/C++ Programm mit CUDA-Erweiterungen
↓
NVCC Compiler
/ \
Host Code Device Code (PTX)
↓ ↓
Host C/C++ JIT-Compiler
Compiler/Linker im Grafiktreiber
↘ ↙
Heterogenes Binary (CPU + GPU)4. Thread-Hierarchie: Grid, Block, Thread, Warp¶
Hierarchie¶
Grid
├── Block (0,0) Block (0,1) ...
│ ├── Thread (0,0,0)
│ ├── Thread (0,0,1)
│ └── ...
└── Block (1,0) ...Grid: Die Gesamtheit aller Threads eines Kernel-Starts. Kann 1D, 2D oder 3D sein.
Block: Eine Gruppe von Threads, die auf einem SM laufen und über Shared Memory kommunizieren können. Bis zu 1024 Threads pro Block (am besten: Vielfaches von 32).
Thread: Die kleinste Ausführungseinheit.
Warp: 32 Threads innerhalb eines Blocks, die der SM als SIMD-Einheit gemeinsam ausführt (Implementierungsdetail, kein Teil des Programmiermodells).
Threads aus verschiedenen Blöcken können nicht direkt miteinander kommunizieren oder synchronisiert werden.
Thread-Indizes¶
Jeder Thread kennt seine Position im Grid über eingebaute Variablen:
| Variable | Bedeutung |
|---|---|
threadIdx.x/y/z | Index des Threads innerhalb seines Blocks |
blockIdx.x/y/z | Index des Blocks innerhalb des Grids |
blockDim.x/y/z | Größe eines Blocks |
gridDim.x/y/z | Größe des Grids |
Globaler 1D-Index:
int i = blockIdx.x * blockDim.x + threadIdx.x;Globaler 2D-Index (für Bilder/Matrizen):
int Row = blockIdx.y * blockDim.y + threadIdx.y;
int Col = blockIdx.x * blockDim.x + threadIdx.x;Transparente Skalierbarkeit¶
Blöcke können in beliebiger Reihenfolge auf beliebige SMs verteilt werden. Es werden typischerweise mehr Threads gestartet, als die GPU gleichzeitig abarbeiten kann – die Hardware verwaltet die Warteschlange automatisch. Das ermöglicht denselben Code auf GPUs verschiedener Größe auszuführen.
5. Warps und Branch-Divergenz¶
Warp-Ausführung¶
Ein SM gruppiert 32 Threads zu einem Warp und führt sie im SIMD-Stil aus: Alle 32 Threads führen zur gleichen Zeit dieselbe Instruktion aus, jedoch auf unterschiedlichen Daten.
Branch-Divergenz¶
Folgt ein if/else innerhalb eines Warps, können einzelne Threads unterschiedliche Pfade nehmen. Da alle Threads eines Warps synchron laufen müssen, wird das folgendermaßen behandelt:
Der Warp führt zuerst den
if-Zweig aus – Threads, die denelse-Zweig nehmen, sind maskiert (inaktiv).Dann wird der
else-Zweig ausgeführt – die anderen Threads sind maskiert.Erst danach laufen wieder alle Threads gemeinsam.
Konsequenz: Beide Zweige werden sequentiell durchlaufen – der Parallelitätsvorteil des Warps geht für die Dauer der Divergenz verloren.

Figure 3:Bearbeitung eines Bildes
Praxisbeispiel: Ein 85×51-Bild, das mit 16×16-Blöcken überdeckt wird, erzeugt Randblöcke, deren Threads teilweise außerhalb des Bildes liegen und durch if (Row < height && Col < width) deaktiviert werden. Das führt zu Branch-Divergenz in 23 von insgesamt allen beteiligten Warps.
Independent Thread Scheduling (ab Volta-Architektur)¶
Ab der Volta-Generation hat jeder Thread einen eigenen Programm-Counter – Threads können innerhalb eines Warps voneinander unabhängig weitergeführt werden (kein erzwungenes Lock-Step mehr). Das erlaubt feinere Synchronisationsmuster innerhalb eines Warps, ändert aber nichts an der Empfehlung, Branch-Divergenz zu minimieren.
Occupancy – Latenz durch Warps verstecken¶
Warum kann die GPU trotz hoher Speicherlatenz hohen Durchsatz erreichen? Weil ein SM viele Warps gleichzeitig vorhält. Wartet ein Warp auf Daten aus dem Global Memory (typisch: 200–800 Zyklen), schaltet der SM sofort auf einen anderen bereiten Warp um – ohne Overhead.
Occupancy bezeichnet den Anteil der aktiv vorgehaltenen Warps an der maximalen Warp-Kapazität eines SM:
Occupancy = aktive Warps / maximale Warps pro SMEin Ampere-SM kann bis zu 64 Warps gleichzeitig vorhalten. Sind nur wenige Warps aktiv (niedrige Occupancy), hat der SM keine Ausweichmöglichkeit bei Speicherwartzeiten → er bleibt idle.
Einflussfaktoren auf die Occupancy:
| Ressource | Effekt bei hohem Verbrauch |
|---|---|
| Register pro Thread | Mehr Register → weniger Threads passen in den SM → niedrigere Occupancy |
| Shared Memory pro Block | Größerer Shared-Memory-Bedarf → weniger Blöcke gleichzeitig aktiv (wird in der nächsten Einheit behandelt) |
| Block-Größe | Zu kleine Blöcke → SM kann nicht alle Warp-Slots füllen |
Hohe Occupancy ist kein Selbstzweck – sie ist ein Mittel, um Speicherlatenzen zu verbergen. Ein Kernel mit sehr wenig Speicherzugriffen kann auch bei niedriger Occupancy gut performen.
6. Speicherverwaltung¶
Speicherhierarchie (Überblick)¶
| Speichertyp | Sichtbar für | Zugriff | Größe |
|---|---|---|---|
| Register | Einzelner Thread | Sehr schnell | Sehr klein (~255 pro Thread) |
| Shared Memory | Alle Threads im Block | Schnell | ~48–192 kB pro SM |
| Global Memory | Alle Threads + Host | Langsam (hohe Latenz) | GB-Bereich |
Der Host (CPU) kann nur auf den Global Memory der GPU zugreifen – per Kopieroperationen.
Memory Coalescing¶
Der Global Memory ist die mit Abstand langsamste Speicherebene. Die Hardware kann jedoch mehrere Zugriffe zusammenfassen, wenn Threads eines Warps auf zusammenhängende Speicheradressen zugreifen:
Coalesced (optimal): Thread 0 liest
A[0], Thread 1 liestA[1], ..., Thread 31 liestA[31]→ eine einzige 128-Byte-Transaktion.Uncoalesced (schlecht): Threads greifen auf verstreute Adressen zu → bis zu 32 separate Transaktionen, Faktor 32 schlechtere Bandbreite.
Typisches Muster – zeilenweiser Zugriff auf eine Matrix:
// GUT: Threads nebeneinander (x) lesen nebeneinander im Speicher (Row-Major)
int Col = blockIdx.x * blockDim.x + threadIdx.x; // variiert schnell
int Row = blockIdx.y * blockDim.y + threadIdx.y; // variiert langsam
float val = A[Row * width + Col]; // benachbarte Threads → benachbarte Adressen ✓
// SCHLECHT: Threads nebeneinander lesen in derselben Spalte
float val = A[Col * width + Row]; // Stride = width → keine Coalescing ✗Im Faltungs-Kernel greifen benachbarte Threads auf benachbarte Pixel zu – das ist automatisch coalesced. Die Faltungsmaske hingegen wird von allen Threads identisch gelesen, weshalb sie ideal in den Constant Memory gehört (nächste Einheit).
CUDA Memory-API¶
Speicher auf der GPU allozieren:
cudaMalloc(void **devPtr, size_t size)
// devPtr: Adresse des Pointers, der auf GPU-Speicher zeigen soll
// size: Größe in ByteGPU-Speicher freigeben:
cudaFree(void *devPtr)Daten zwischen Host und Device kopieren:
cudaMemcpy(void *dst, const void *src, size_t count, cudaMemcpyKind kind)
// kind: cudaMemcpyHostToDevice | cudaMemcpyDeviceToHost | cudaMemcpyDeviceToDevicecudaMemcpy ist blockierend – der Host wartet, bis die Übertragung abgeschlossen ist.
Fehlerbehandlung¶
Alle CUDA-API-Funktionen geben cudaError_t zurück. Kernel-Starts hingegen berichten Fehler nicht synchron – sie kehren sofort zurück, Laufzeitfehler des Kernels (z. B. ungültige Speicherzugriffe) können erst danach abgefragt werden.
// API-Fehler direkt prüfen
cudaError_t err = cudaMalloc(&d_A, size);
if (err != cudaSuccess) {
fprintf(stderr, "cudaMalloc fehlgeschlagen: %s\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Kernel-Fehler nach dem Start abfragen
vecAddKernel<<<Grid, Block>>>(d_A, d_B, d_C, n);
err = cudaGetLastError(); // prüft Fehler beim Kernel-Start (z.B. ungültige Dimensionen)
if (err != cudaSuccess) { ... }
cudaDeviceSynchronize(); // wartet auf Abschluss und meldet Laufzeitfehler
err = cudaGetLastError(); // jetzt auch Kernel-Laufzeitfehler sichtbar
if (err != cudaSuccess) { ... }Wichtig: Ohne explizite Fehlerprüfung schlägt ein CUDA-Programm lautlos fehl – falsche Ergebnisse statt Fehlermeldung. In Produktionscode sollte jeder API-Aufruf geprüft werden.
7. Erstes vollständiges Beispiel: Vektor-Addition¶
Kernel (Device Code)¶
// Jeder Thread addiert genau ein Paar A[i] + B[i]
__global__ void vecAddKernel(float *A, float *B, float *C, int n)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n)
C[i] = A[i] + B[i];
}Der if (i < n)-Check ist wichtig: Das Grid wird auf ganze Blöcke aufgerundet – überschüssige Threads dürfen nicht in ungültigen Speicher schreiben.
Host Code (vollständig)¶
void vecAdd(float *h_A, float *h_B, float *h_C, int n)
{
int size = n * sizeof(float);
float *d_A, *d_B, *d_C;
// Part 1: Speicher auf GPU allozieren und Daten kopieren
cudaMalloc((void **) &d_A, size);
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMalloc((void **) &d_B, size);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
cudaMalloc((void **) &d_C, size);
// Part 2: Kernel starten
dim3 DimGrid((n - 1) / 256 + 1, 1, 1); // Blöcke = ceil(n/256)
dim3 DimBlock(256, 1, 1);
vecAddKernel<<<DimGrid, DimBlock>>>(d_A, d_B, d_C, n);
// Part 3: Ergebnis zurückkopieren und Speicher freigeben
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
cudaFree(d_A); cudaFree(d_B); cudaFree(d_C);
}Grid-Dimensionen berechnen¶
// Variante 1: ceil()-Funktion
vecAddKernel<<<ceil(n / 256.0), 256>>>(d_A, d_B, d_C, n);
// Variante 2: Integer-Arithmetik (äquivalent, bevorzugt)
dim3 DimGrid((n - 1) / 256 + 1, 1, 1);
dim3 DimBlock(256, 1, 1);
vecAddKernel<<<DimGrid, DimBlock>>>(d_A, d_B, d_C, n);8. Synchronisation¶
Kernel-Start ist asynchron¶
Der Kernel-Start (<<<...>>>) kehrt sofort zurück, ohne auf den Abschluss der GPU-Berechnung zu warten. Das hat Konsequenzen für Zeitmessungen:
// FALSCH: misst nur die Kernel-Startzeit, nicht die Ausführungszeit
gettimeofday(&begin, NULL);
vecAddKernel<<<Grid, Block>>>(d_A, d_B, d_C, n);
gettimeofday(&mid, NULL); // mid ≈ begin (Kernel läuft noch!)
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
gettimeofday(&end, NULL); // end - begin = Kernel + Copy
// RICHTIG: explizit warten
gettimeofday(&begin, NULL);
vecAddKernel<<<Grid, Block>>>(d_A, d_B, d_C, n);
cudaDeviceSynchronize(); // blockiert, bis Kernel fertig
gettimeofday(&mid, NULL); // mid - begin = Kernel-Zeit
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
gettimeofday(&end, NULL); // end - mid = Copy-ZeitcudaMemcpy selbst ist blockierend – es wartet intern auf den Abschluss aller vorherigen Kernel, bevor es kopiert. cudaDeviceSynchronize macht das explizit.
9. 2D-Daten: Bilder und Matrizen¶
Row-Major Layout¶
C/C++ speichert mehrdimensionale Arrays zeilenweise (Row-Major). Der lineare Index eines Elements [Row][Col] einer Matrix der Breite Width ist:
Index = Row * Width + Col
// Beispiel: Element [2][1] in einer 4×4-Matrix: 2*4 + 1 = 92D-Kernel: Bild skalieren¶
__global__ void PictureKernel(float *d_Pin, float *d_Pout, int height, int width)
{
int Row = blockIdx.y * blockDim.y + threadIdx.y;
int Col = blockIdx.x * blockDim.x + threadIdx.x;
if (Row < height && Col < width)
d_Pout[Row * width + Col] = 2.0f * d_Pin[Row * width + Col];
}// Host: 2D-Grid für ein n×m-Bild mit 16×16-Blöcken
dim3 DimGrid((n - 1) / 16 + 1, (m - 1) / 16 + 1, 1);
dim3 DimBlock(16, 16, 1);
PictureKernel<<<DimGrid, DimBlock>>>(d_Pin, d_Pout, m, n);10. Anwendungsbeispiel: Faltung (Convolution)¶
Was ist Faltung?¶
Faltung ist eine Array-Operation, bei der jedes Ausgabeelement eine gewichtete Summe benachbarter Eingabelemente ist. Die Gewichte werden durch eine Faltungsmaske (auch: Kernel, Filter) definiert.
Anwendungen:
Bildverarbeitung: Glätten, Schärfen, Kantenerkennung (z. B. Gauß-Filter).
Signalverarbeitung: Audio-Filter.
Deep Learning: Faltungsschichten in CNNs (Convolutional Neural Networks).
1D-Faltung¶
Für ein Eingabe-Array N und eine Maske M der Breite Mask_Width:
P[i] = N[i - Mask_Width/2] * M[0]
+ N[i - Mask_Width/2 + 1] * M[1]
+ ...
+ N[i + Mask_Width/2] * M[Mask_Width-1]Beispiel mit M = [3, 4, 5, 4, 3] und N = [1, 2, 3, 4, 5, 6, 7]:
P[2] = N[0]*3 + N[1]*4 + N[2]*5 + N[3]*4 + N[4]*3
= 1*3 + 2*4 + 3*5 + 4*4 + 5*3 = 3+8+15+16+15 = 57Randbehandlung (Ghost-Elements)¶
An den Rändern des Arrays fehlen Nachbarn. Übliche Strategien:
Zero-Padding: Fehlende Elemente werden als
0behandelt (einfachste Variante).Clamp: Randwerte werden wiederholt.
Mirror: Array wird an den Rändern gespiegelt.
1D-Faltungs-Kernel (GPU, Zero-Padding)¶
__global__ void convolution_1D_basic_kernel(float *N, float *M,
float *P, int Mask_Width, int Width)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
float Pvalue = 0.0f;
int N_start = i - (Mask_Width / 2);
if (i < Width) {
for (int j = 0; j < Mask_Width; j++) {
if (N_start + j >= 0 && N_start + j < Width)
Pvalue += N[N_start + j] * M[j];
// fehlende Elemente implizit 0 (kein else-Zweig nötig)
}
P[i] = Pvalue;
}
}2D-Faltungs-Kernel (GPU, Zero-Padding)¶
__global__ void convolution_2D_basic_kernel(unsigned char *in, unsigned char *mask,
unsigned char *out,
int maskwidth, int w, int h)
{
int Col = blockIdx.x * blockDim.x + threadIdx.x;
int Row = blockIdx.y * blockDim.y + threadIdx.y;
if (Col < w && Row < h) {
int pixVal = 0;
int N_start_col = Col - (maskwidth / 2);
int N_start_row = Row - (maskwidth / 2);
for (int j = 0; j < maskwidth; j++) {
for (int k = 0; k < maskwidth; k++) {
int curRow = N_start_row + j;
int curCol = N_start_col + k;
if (curRow >= 0 && curRow < h && curCol >= 0 && curCol < w)
pixVal += in[curRow * w + curCol] * mask[j * maskwidth + k];
}
}
out[Row * w + Col] = (unsigned char) pixVal;
}
}Hinweis: Diese Basisimplementierung liest für jedes Ausgabeelement alle benötigten Eingabewerte aus dem langsamen Global Memory. Eine optimierte Version würde die Faltungsmaske in den Constant Memory und die Eingabedaten in den Shared Memory laden – das ist Thema der nächsten Einheit.
11. Zusammenfassung¶
| Konzept | Kernidee | CUDA-Schlüsselwort/-API |
|---|---|---|
| Kernel | GPU-Funktion, von allen Threads ausgeführt | __global__ |
| Thread-Hierarchie | Grid → Block → Thread | blockIdx, threadIdx, blockDim |
| Speicherverwaltung | Host alloziert/kopiert GPU-Speicher | cudaMalloc, cudaMemcpy, cudaFree |
| Kernel-Start | Asynchron; Grid/Block-Dimensionen als dim3 | <<<DimGrid, DimBlock>>> |
| Synchronisation | Explizit warten auf GPU | cudaDeviceSynchronize |
| Warp | 32 Threads, SIMD-Ausführung | (Implementierungsdetail) |
| Branch-Divergenz | If/Else im Warp → sequentielle Abarbeitung | Vermeiden durch datenunabhängige Pfade |
| Occupancy | Aktive Warps / max. Warps pro SM; versteckt Speicherlatenz | Abhängig von Registern, Shared Memory, Block-Größe |
| Memory Coalescing | Benachbarte Threads → benachbarte Adressen = eine Transaktion | Row-Major-Zugriff; Stride-1-Muster bevorzugen |
| Fehlerbehandlung | Kernel-Fehler sind asynchron, API-Fehler synchron | cudaGetLastError, cudaGetErrorString |
| Faltung | Gewichtete Summe über Nachbarn | Maske × Eingabe → Ausgabe |