Kurseinheit 1: SIMD-Instruktionen
Einleitung¶
Willkommen zur ersten Einheit des Moduls Advanced Parallel Programming. In diesem Teil beschäftigen wir uns mit der Parallelität innerhalb des Prozessors, wobei der Fokus auf SIMD (Single Instruction, Multiple Data) bei modernen CPUs liegt.
Während wir in der parallelen Programmierung oft die Verteilung auf verschiedene Tasks oder Threads betrachten, gibt es auch Parallelität innerhalb eines einzelnen Prozessors. SIMD gehört zur Klasse der Datenebenen-Parallelität: Dieselbe Anweisung wird gleichzeitig auf eine ganze Sammlung von Daten angewendet, was besonders für die Effizienz von Schleifen in modernen Vektorarchitekturen entscheidend ist. Die verschiedenen Arten der Parallelität werden in Abschnitt 1 genauer eingeordnet.
Lernziele¶
Nach Abschluss dieser Kurseinheit werden Sie in der Lage sein, folgende Themen zu verstehen und anzuwenden:
SIMD/Vektor-Operationen: Sie verstehen das Konzept von Single Instruction, Multiple Data und können den Unterschied zu skalaren Operationen erklären.
Flynn’sche Taxonomie: Sie können SIMD in das klassische Schema der Rechnerarchitekturen (neben SISD, MISD und MIMD) einordnen.
Auto-Vektorisierung: Sie wissen, wie moderne Compiler Code automatisch optimieren und welche Voraussetzungen dafür erfüllt sein müssen.
Intrinsische Operationen: Sie kennen die Möglichkeit, SIMD-Befehle explizit im Programmcode zu nutzen.
OpenMP SIMD: Sie verstehen, wie Compiler-Direktiven zur Unterstützung der Vektorisierung eingesetzt werden.
Hardware-Grundlagen: Sie haben einen Überblick über gängige Vektoreinheiten (wie SSE, AVX, AVX-512) und wissen, wie Sie die Fähigkeiten Ihrer eigenen CPU prüfen können.
Datenorganisation: Sie kennen den Unterschied zwischen Array of Structures (AoS) und Structure of Arrays (SoA) und können erklären, warum SoA für SIMD entscheidend sein kann.
Praxistechniken: Sie wissen, wie aligned Speicher allokiert wird und wie Loop-Tail-Situationen (Array-Größe kein Vielfaches der Vektorbreite) korrekt behandelt werden.
1. Theoretische Grundlagen: Arten der Parallelität¶
Bevor wir uns im Detail mit SIMD-Instruktionen beschäftigen, ist es wichtig, die verschiedenen Formen der Parallelität zu verstehen, die in modernen Systemen zum Einsatz kommen. Man unterscheidet grundlegend drei Arten:
Parallelisierung auf Datenebene (Data Level Parallelism): Hierbei werden mehrere Datenelemente gleichzeitig verarbeitet. Dies ist der Hauptfokus dieser Kurseinheit.
Parallelisierung auf Taskebene (Task Level Parallelism): Verschiedene Aufgaben oder Programmteile werden gleichzeitig ausgeführt. Dieses Thema wird in den späteren Teilen dieses Moduls (Teil 2 und 3) vertieft.
Temporäre Parallelität: Eine einzelne Aufgabe wird in aufeinanderfolgende Schritte unterteilt, die wie am Fließband abgearbeitet werden. Ein klassisches Beispiel hierfür ist das Pipelining in modernen Prozessoren.
Innerhalb eines einzelnen Prozessors finden wir diese Konzepte in verschiedenen Ausprägungen wieder:
Instruction Level Parallelism (ILP): Nutzt Pipelining und spekulative Ausführung, um Befehle parallel abzuarbeiten.
Vektorarchitekturen & SIMD: Führen dieselbe Anweisung auf einer ganzen Sammlung von Daten aus (auch GPUs nutzen dieses Prinzip).
Thread-Level Parallelism: Nutzt mehrere Hardware-Threads oder Hyperthreading, um mehrere Kontrollflüsse gleichzeitig zu bedienen.
2. Einordnung nach Flynn’s Taxonomie¶
Um Rechnerarchitekturen und ihre Parallelisierungsfähigkeiten zu klassifizieren, nutzt man die Flynn’sche Taxonomie. Sie unterscheidet Systeme anhand der Anzahl der Instruktions- und Datenströme, wie in Tabelle 1 undAbbildung 1 dargestellt.
Table 1:Flynn’sche Taxonomie als Tabelle
| Klassifizierung | Bedeutung | Architektur-Beispiel |
|---|---|---|
| SISD | Single Instruction, Single Data | Klassischer von Neumann Rechner |
| SIMD | Single Instruction, Multiple Data | Vektorrechner / Moderne CPU-Vektoreinheiten |
| MISD | Multiple Instruction, Single Data | Gilt als praktisch leere Klasse; theoretisches Beispiel: fehlertolerante Systeme mit redundanter Ausführung und Voting |
| MIMD | Multiple Instruction, Multiple Data | Multiprozessorsysteme / Multi-Core CPUs |
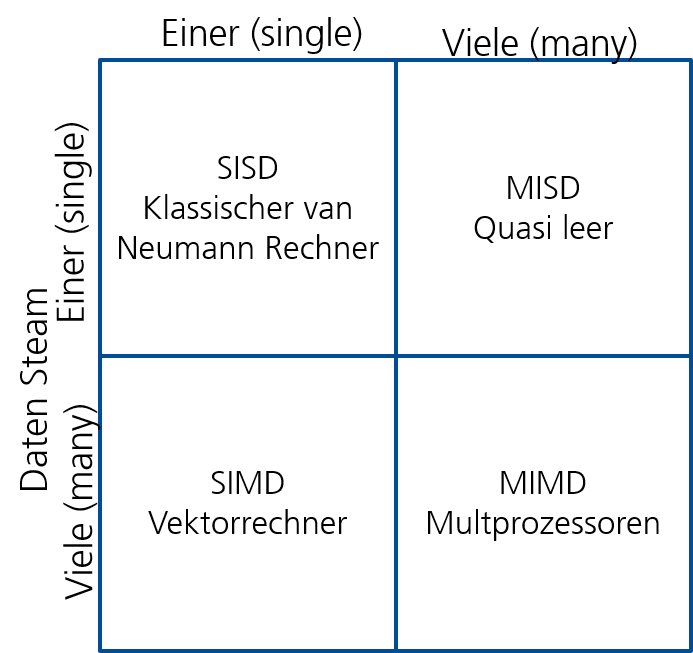
Figure 1:Darstellung der Flynn’schen Taxonomie
In dieser Einheit konzentrieren wir uns auf SIMD. Das Besondere hierbei ist, dass ein einziger Instruktions-Stream (der Befehl) auf viele Daten-Streams gleichzeitig angewendet wird.
3. Skalare vs. Vektor-Operationen¶
Um den Vorteil von SIMD zu verdeutlichen, vergleichen wir eine einfache Vektoraddition: ():
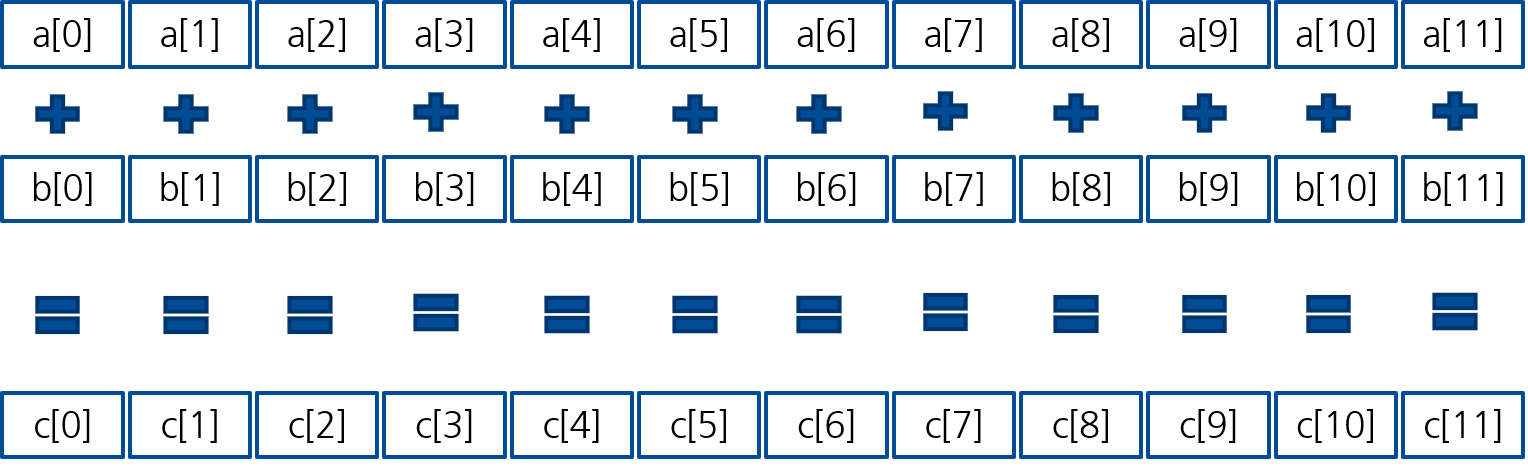
Figure 2:Vektorisierte Addition: Elemente auf einmal!
Skalare Verarbeitung (SISD)¶
In einer klassischen Schleife wird jede Addition einzeln nacheinander ausgeführt:
for(i = 0; i < 12; i++) {
c[i] = a[i] + b[i];
}Der Prozessor lädt a[0] und b[0], addiert sie zu c[0], und wiederholt dies dann für Index 1, 2, 3 usw. Bei 12 Elementen sind 12 separate Additionsbefehle nötig, wie in Abbildung 3 dargestellt.
Figure 3:Skalare Addition: Element für Element
Vektor-Verarbeitung (SIMD)¶
Mit SIMD-Instruktionen (Vektor-Instruktionen) kann der Prozessor mehrere Elemente in einem einzigen Schritt verarbeiten. Besitzt die CPU beispielsweise eine Vektoreinheit, die 4 Ganzzahlen gleichzeitig verarbeiten kann, reduziert sich die Anzahl der benötigten Rechenoperationen drastisch:
Schritt 1: Addiere
a[0...3]undb[0...3]gleichzeitig zuc[0...3].Schritt 2: Addiere
a[4...7]undb[4...7]gleichzeitig zuc[4...7].Schritt 3: Addiere
a[8...11]undb[8...11]gleichzeitig zuc[8...11].
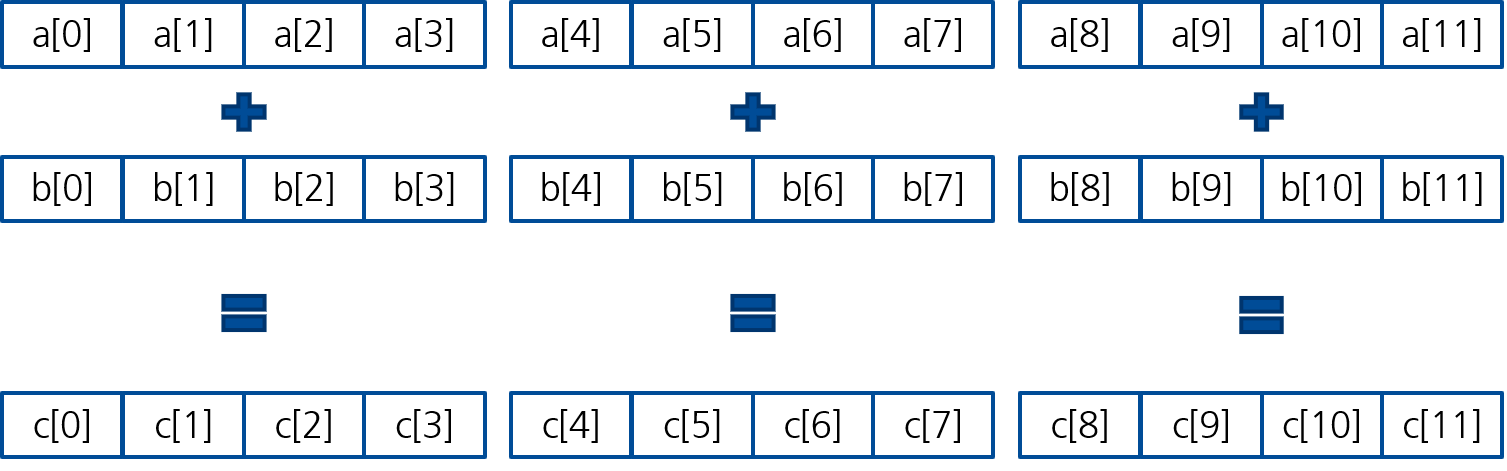
Figure 4:Vektorisierte Addition: immer 4 Elemente
Statt 12 Operationen werden nur noch 3 Vektor-Operationen benötigt.
4. SIMD-Hardware: Vektoreinheiten im Überblick¶
Moderne Prozessoren besitzen spezielle Vektoreinheiten, die eigene Befehlssatzerweiterungen (Instruction Set Extensions) und dedizierte Register nutzen. Die bekanntesten Familien dieser Erweiterungen sind:
| Technologie | Vektorbreite (Bit) | Typische CPU-Generationen (Beispiele) |
|---|---|---|
| SSE (1 bis 4.x) | 128 Bit | Intel: Core 2, Nehalem; AMD: K7, K8 |
| AVX | 256 Bit | Intel: Sandy Bridge, Ivy Bridge; AMD: Bulldozer |
| AVX2 | 256 Bit | Intel: Haswell, Skylake; AMD: Zen, Zen 2, Zen 3 |
| AVX-512 | 512 Bit | Intel: Skylake-X, Xeon Scalable; AMD: Zen 4 |
Was bedeuten diese Bit-Breiten?¶
Die Bit-Breite bestimmt, wie viele Datenelemente gleichzeitig verarbeitet werden können. Ein 32-Bit-Integer (Ganzzahl) benötigt beispielsweise 4 Byte.
128 Bit (SSE): Kann Integer gleichzeitig verarbeiten.
256 Bit (AVX/AVX2): Kann Integer gleichzeitig verarbeiten.
512 Bit (AVX-512): Kann Integer gleichzeitig verarbeiten.
Neben der x86-Welt (Intel/AMD) gibt es ähnliche Technologien auch für andere Architekturen, wie NEON oder SVE bei ARM sowie die Vector Extension bei RISC-V.
5. Praxistipp: Was unterstützt meine CPU?¶
Bevor man Code für SIMD optimiert, muss man wissen, welche Befehlssätze auf der Zielhardware überhaupt verfügbar sind.
Unter Linux¶
In Linux-Systemen kannst du die CPU-Informationen direkt aus dem virtuellen Dateisystem auslesen. Nutze dafür das Terminal:
cat /proc/cpuinfo | grep flagsSuche in der Ausgabe nach Kürzeln wie sse, avx, avx2 oder avx512f.
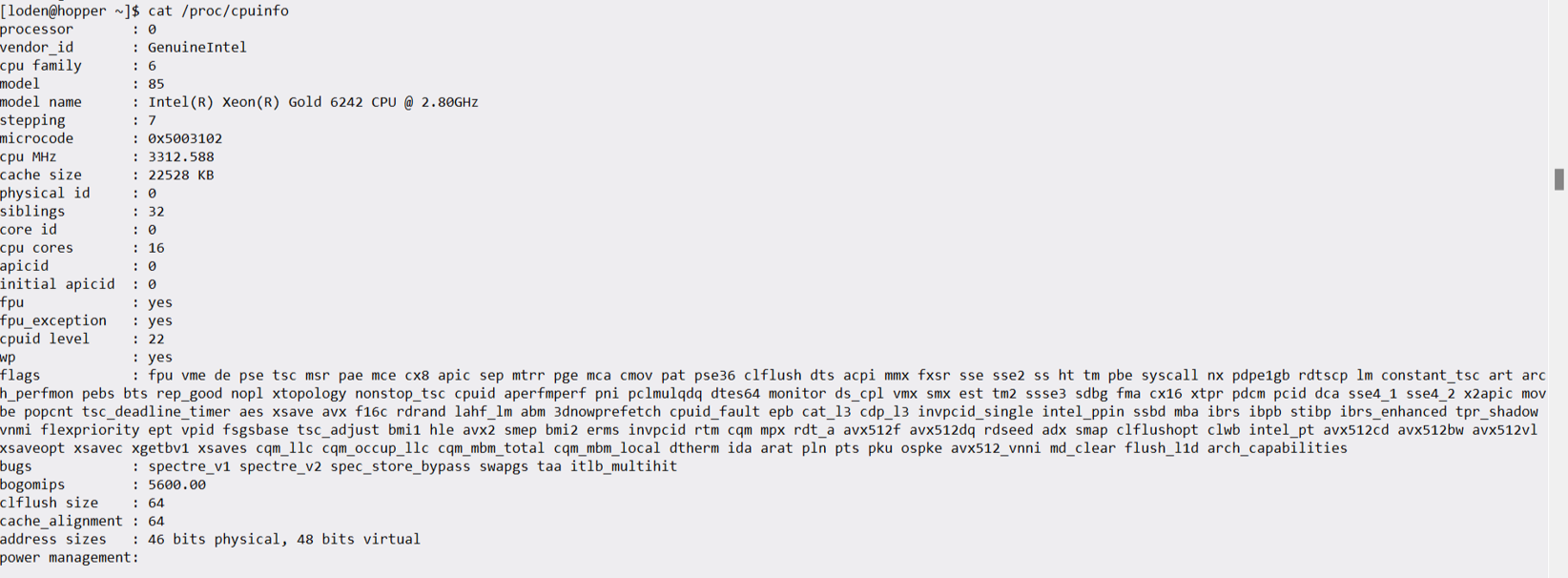
Figure 5:Screenshot cat /proc/cpuinfo
Unter Windows¶
Für Windows-Nutzer ist das Tool CPU-Z (https://
Figure 6:Ausschnitt: ZCPU
6. Auswirkungen auf die Softwareentwicklung¶
Die Existenz dieser Vektoreinheiten bedeutet für uns als Entwickler zweierlei:
Neue Assembler-Befehle & Register: Es gibt spezifische Befehle (z. B.
vpadddfür Vektor-Addition) und Register (z. B.ymm0–ymm15bei AVX2), die direkt angesprochen werden können.Compiler-Unterstützung: Wir müssen nicht zwingend Assembler schreiben. Moderne Compiler versuchen, unseren Code automatisch zu „vektorisieren“, sofern wir ihnen die richtigen Anweisungen (Flags) geben.
Das Code-Beispiel (C)¶
Der folgende C-Code dient als Grundlage für beide Übersetzungsarten:
void sum512(int* a, int *b, int *c) {
for (int i = 0; i < 512; i++) {
c[i] = a[i] + b[i];
}
}1. Nicht-vektorisierte Version (Skalar)¶
Ohne spezielle Optimierungen verarbeitet der Prozessor jedes Element einzeln.
Auszug aus dem Assembler-Code:
xor rax, rax ; rax = 0 (Byte-Offset, Startwert)
.L2:
mov ecx, DWORD PTR [rsi+rax] ; Lädt a[i]
add ecx, DWORD PTR [rdi+rax] ; Addiert b[i]
mov DWORD PTR [rdx+rax], ecx ; Speichert in c[i]
add rax, 4 ; Nächster Index (4 Byte pro int)
cmp rax, 2048 ; Ende bei 512 * 4 = 2048 Byte erreicht?
jne .L2Charakteristik: Jede Iteration führt genau eine Addition aus.
Register: Es werden Standard-32-Bit-Register wie
eaxoderecxgenutzt.
2. Vektorisierte Version (SIMD / AVX2)¶
Wird die Vektorisierung aktiviert, nutzt der Prozessor breitere Register (hier: AVX2 mit 256 Bit). Da ein int 4 Byte (32 Bit) groß ist, können 8 Werte gleichzeitig verarbeitet werden ().
Auszug aus dem Assembler-Code:
.L3:
vmovdqu ymm0, YMMWORD PTR [rsi+rax] ; Lädt 8 Werte gleichzeitig
vpaddd ymm0, ymm0, YMMWORD PTR [rdi+rax] ; Addiert 8 Werte gleichzeitig
vmovdqu YMMWORD PTR [rdx+rax], ymm0 ; Speichert 8 Werte gleichzeitig
add rax, 32 ; Nächster Block (8 * 4 = 32 Byte)
cmp rax, 2048
jne .L3vmovdqu: Lädt/speichert einen ganzen Vektor (256 Bit) in ein Vektorregister (
ymm0).vpaddd: Führt die Vektoraddition für alle enthaltenen Elemente in einem Schritt aus.
Vorteil: Die Schleife muss nur noch 64-mal durchlaufen werden () statt 512-mal.
3. Compiler-Flags für die Vektorisierung (GCC)¶
Damit der Compiler diesen optimierten Code erzeugt, müssen oft spezifische Flags gesetzt werden:
-ftree-vectorize: Aktiviert die automatische Vektorisierung (in-O3bereits enthalten).-march=nativeoder-march=skylake-avx512: Optimiert den Code spezifisch für die Architektur deiner CPU und aktiviert entsprechende Befehlssätze automatisch-mavx2/-mavx512f: Aktiviert explizit bestimmte SIMD-Erweiterungen.-fopt-info-vec: Gibt Rückmeldung darüber, welche Schleifen erfolgreich vektorisiert wurden.
Exkurs: Vektorisierung mit dem Clang-Compiler¶
Clang nutzt das LLVM-Backend und verfügt über sehr leistungsfähige Analyse-Tools für die Vektorisierung. Die meisten Flags von GCC funktionieren auch hier, aber es gibt nützliche Zusatzoptionen.
1. Grundlegende Flags (wie bei GCC)¶
-O3: Aktiviert die höchste Optimierungsstufe, inklusive des “Loop Vectorizers” und des “SLP Vectorizers” (Superword-Level Parallelism).-march=native: Erlaubt Clang, alle SIMD-Features der aktuellen CPU (SSE4, AVX2 etc.) zu nutzen.-mavx2,-msse4.1: Aktiviert gezielt bestimmte Befehlssätze.
2. Clang-spezifische Diagnose¶
Clang ist bekannt für seine detaillierten Fehlermeldungen und Optimierungsberichte. Wenn du wissen willst, warum eine Schleife nicht vektorisiert wurde, helfen diese Flags:
-Rpass=loop-vectorize: Gibt eine Rückmeldung, welche Schleifen erfolgreich vektorisiert wurden.-Rpass-missed=loop-vectorize: Zeigt an, welche Schleifen nicht vektorisiert werden konnten.-Rpass-analysis=loop-vectorize: Liefert eine detaillierte Begründung, warum die Vektorisierung abgelehnt wurde (z. B. wegen zu komplexer Datenabhängigkeiten).
3. Erzwungene Vektorisierung via Pragma¶
In Clang kannst du dem Compiler direkt im Quellcode “Hinweise” geben, wenn er sich bei einer Schleife unsicher ist:
#pragma clang loop vectorize(enable)
for (int i = 0; i < 512; i++) {
c[i] = a[i] + b[i];
}Zusätzlich kann man mit #pragma clang loop interleave(enable) das Unrolling von Schleifen erzwingen, was oft Hand in Hand mit SIMD geht.
Zusammenfassung der Compiler-Optionen¶
| Feature | GCC Flag | Clang Flag |
|---|---|---|
| Optimierung | -O3 | -O3 |
| CPU-Architektur | -march=native | -march=native |
| Erfolgsbericht | -fopt-info-vec | -Rpass=loop-vectorize |
| Misserfolgs-Analyse | -fopt-info-vec-missed | -Rpass-analysis=loop-vectorize |
7. indernisse für die Auto-Vektorisierung¶
Es gibt drei Hauptgründe, warum ein Compiler “aufgibt” und stattdessen langsamen, skalaren Code erzeugt:
A. Datenabhängigkeiten (Data Dependencies)¶
Das größte Problem ist, wenn ein Rechenschritt vom Ergebnis des vorherigen abhängt. Beispiel (Loop-Carried Dependency):
for (int i = 1; i < 512; i++) {
a[i] = a[i-1] + b[i]; // i hängt von i-1 ab
}Hier kann der Compiler nicht 8 Werte gleichzeitig berechnen, da er für a[1] das fertige Ergebnis von a[0] braucht, für a[2] das von a[1] usw. Eine Parallelisierung würde das Ergebnis verfälschen.
B. Speicher-Alignment (Data Alignment)¶
Vektoreinheiten arbeiten am effizientesten, wenn die Daten im Arbeitsspeicher an Adressen liegen, die durch die Vektorbreite teilbar sind (z. B. 32-Byte-Grenzen für AVX).
Sind die Daten “unaligned”, muss der Compiler oft extra Code einfügen, um die Daten mühsam zusammenzusuchen, was den Performance-Gewinn wieder auffrisst.
C. Kontrollfluss (Control Flow) innerhalb der Schleife¶
if-else-Bedingungen innerhalb einer Schleife sind “Gift” für einfache Vektorisierung.
for (int i = 0; i < 512; i++) {
if (a[i] > 0) {
c[i] = a[i] + b[i];
} else {
c[i] = b[i];
}
}Da ein SIMD-Befehl dieselbe Operation auf alle Daten anwendet, kann er nicht für den einen Teil des Vektors addieren und für den anderen nichts tun – außer die Hardware unterstützt Maskierung (wie AVX-512), was aber komplexer in der Umsetzung ist.
D. Pointer-Aliasing und das restrict-Schlüsselwort¶
Ein weiteres häufiges Hindernis ist Pointer-Aliasing: Wenn eine Funktion zwei Zeiger a und b erhält, muss der Compiler grundsätzlich davon ausgehen, dass diese auf denselben oder überlappenden Speicherbereich zeigen könnten.
void add(int *a, int *b, int *c, int n) {
for (int i = 0; i < n; i++) {
c[i] = a[i] + b[i]; // Was, wenn c == a?
}
}Zeigt c auf denselben Speicher wie a, würde Iteration i den Wert überschreiben, den Iteration i+1 noch lesen muss. Eine Vektorisierung wäre dann falsch. Der Compiler ist deshalb gezwungen, skalaren Code zu erzeugen — auch wenn die Zeiger im konkreten Aufruf gar nicht überlappen.
Die Lösung ist das C99-Schlüsselwort restrict, mit dem man dem Compiler garantiert, dass die Zeiger nicht überlappen:
void add(int * restrict a, int * restrict b, int * restrict c, int n) {
for (int i = 0; i < n; i++) {
c[i] = a[i] + b[i];
}
}Mit restrict kann der Compiler die Schleife bedenkenlos vektorisieren. In C++ gibt es kein standardisiertes restrict, aber GCC und Clang akzeptieren __restrict__ als Erweiterung.
Achtung:
restrictist ein Versprechen an den Compiler. Überlappen die Zeiger trotzdem, ist das Verhalten undefiniert — die Korrektheit liegt beim Programmierer.
8. Datenorganisation: Structure of Arrays vs. Array of Structures¶
Neben den Hindernissen aus Abschnitt 7 gibt es einen weiteren, oft unterschätzten Faktor, der über Erfolg oder Misserfolg der Vektorisierung entscheidet: wie die Daten im Speicher angeordnet sind.
Das Problem: Array of Structures (AoS)¶
Die intuitive Art, eine Sammlung von Objekten zu speichern, ist ein Array von Strukturen:
typedef struct {
float x, y, z; // Position
float vx, vy, vz; // Geschwindigkeit
} Particle;
Particle particles[N];Im Speicher liegen die Daten dann so:
x0 y0 z0 vx0 vy0 vz0 | x1 y1 z1 vx1 vy1 vz1 | x2 ...Wenn wir nun alle x-Koordinaten mit AVX2 (8 Floats) addieren wollen, müssen wir x0, x1, ..., x7 laden — diese liegen aber nicht nebeneinander, sondern jeweils 6 Floats (24 Byte) auseinander. Der Compiler kann keine einfache vmovdqu-Instruktion verwenden, sondern muss aufwändige Gather-Operationen einsetzen oder scheitert an der Vektorisierung ganz.
Die Lösung: Structure of Arrays (SoA)¶
Statt einem Array von Strukturen legt man ein Array pro Feld an:
typedef struct {
float x[N], y[N], z[N];
float vx[N], vy[N], vz[N];
} Particles;
Particles particles;Im Speicher liegen die Daten nun so:
x0 x1 x2 x3 x4 x5 x6 x7 | x8 x9 ... (alle x hintereinander)
y0 y1 y2 y3 y4 y5 y6 y7 | y8 y9 ... (alle y hintereinander)
...Jetzt kann der Compiler x0 bis x7 mit einer einzigen Vektorlade-Instruktion laden. Die Schleife
for (int i = 0; i < N; i++) {
particles.x[i] += particles.vx[i] * dt;
}wird problemlos vektorisiert, da alle Zugriffe streng sequenziell und zusammenhängend sind.
Vergleich und Abwägung¶
| AoS | SoA | |
|---|---|---|
| SIMD-Tauglichkeit | schlecht (Scatter/Gather nötig) | sehr gut (sequenzielle Zugriffe) |
| Code-Lesbarkeit | intuitiv (p.x, p.y) | weniger intuitiv |
| Cache-Verhalten (ein Objekt) | gut (alle Felder eines Objekts nah) | schlecht |
| Cache-Verhalten (ein Feld, viele Objekte) | schlecht | sehr gut |
Die Wahl hängt vom Zugriffsmuster ab: Wird immer nur ein Objekt vollständig verarbeitet (z.B. Kollisionsprüfung zweier Partikel), ist AoS besser. Werden ein Feld über viele Objekte verarbeitet (z.B. alle Positionen updaten), ist SoA die richtige Wahl — und in der numerischen Simulation ist Letzteres die Regel.
Faustregel: SIMD-freundlicher Code arbeitet auf einem Feld vieler Objekte, nicht auf vielen Feldern eines Objekts.
Übungsaufgabe: Gegeben ist folgende AoS-Struktur für 2D-Vektoren:
typedef struct { float x; float y; } Vec2;
Vec2 a[512], b[512], c[512];Schreiben Sie die Struktur in SoA-Form um und implementieren Sie die Addition c = a + b so, dass der Compiler sie automatisch vektorisieren kann.
9. Vertiefung: Intrinsische Funktionen (Intrinsics)¶
Wenn die Auto-Vektorisierung scheitert, bieten Intrinsics die maximale Kontrolle. Sie sind im Header <immintrin.h> definiert.
Datentypen in Intrinsics¶
Die Hardware nutzt spezielle Register, für die es in C entsprechende Datentypen gibt:
__m128/__m128d/__m128i: 128-Bit (4 Floats / 2 Doubles / Integer).__m256/__m256d/__m256i: 256-Bit (8 Floats / 4 Doubles / Integer).__m512/__m512d/__m512i: 512-Bit (16 Floats / 8 Doubles / Integer).
Das Namensschema¶
Die Funktionen sind streng nach folgendem Muster benannt:
_mm<Bitbreite>_<Operation>_<Suffix>
Gängige Suffixe:
ps: packed single (32-Bit Float)pd: packed double (64-Bit Float)epi32/epi64: extended packed integer (32/64-Bit)i<Breite>: integer (z. B.i256)u<Breite>: unsigned interger (z. B.u32)
Load & Store: Die Alignment-Falle¶
Ein kritischer Punkt aus den Folien ist der Unterschied zwischen Aligned und Unaligned Memory Access:
_mm512_load_epi32: Erwartet, dass die Daten an einer 64-Byte-Grenze im RAM liegen. Auf älteren Architekturen führt ein Verstoß dagegen zu einem Laufzeitfehler (Segfault); auf modernen CPUs (ab Intel Ice Lake / AMD Zen 4) ist der Unterschied zuloadumeist nur ein Performanceverlust._mm512_loadu_epi32: Erlaubt unalignierte Daten (“u”) und ist die sichere Wahl, solange kein Alignment garantiert werden kann.
Beispiel für eine AVX-512 Loop:
for (int i = 0; i < n; i += 16) {
// Laden von 16 Integern (16 * 4 Byte = 64 Byte)
__m512i a_vec = _mm512_load_epi32(&a[i]);
__m512i b_vec = _mm512_load_epi32(&b[i]);
// Vektor-Addition
__m512i res = _mm512_add_epi32(a_vec, b_vec);
// Speichern
_mm512_store_epi32(&c[i], res);
}Aligned Memory in der Praxis: Allokation¶
Da _mm512_load_epi32 ausgerichteten Speicher voraussetzt, stellt sich die Frage, wie man aligned Speicher in C/C++ allokiert. Das normale malloc garantiert keine bestimmte Ausrichtung über die Grundausrichtung hinaus.
Möglichkeit 1: aligned_alloc (C11/C++17)
// Allokiert n * sizeof(int) Bytes, ausgerichtet auf 64 Byte (für AVX-512)
int *a = (int *) aligned_alloc(64, n * sizeof(int));
// ...
free(a);Möglichkeit 2: posix_memalign (POSIX)
int *a;
posix_memalign((void **)&a, 64, n * sizeof(int));
// ...
free(a);Möglichkeit 3: _mm_malloc (Intel-spezifisch, aber weit verbreitet)
int *a = (int *) _mm_malloc(n * sizeof(int), 64);
// ...
_mm_free(a); // Nicht free()!Stack-Arrays mit alignas (C11/C++11)
#include <stdalign.h>
alignas(64) int a[512]; // Auf Stack, 64-Byte-alignedLoop-Tail: Was tun mit dem Rest?¶
In der Praxis ist die Array-Größe selten ein Vielfaches der Vektorbreite. AVX2 verarbeitet 8 int-Werte pro Iteration — was passiert bei 513 Elementen?
Strategie 1: Skalarer Fallback (einfachste Lösung)
Die Hauptschleife verarbeitet so viele vollständige Vektoren wie möglich; die verbleibenden Elemente werden skaliar abgearbeitet:
int n = 513;
int vec_width = 8; // AVX2: 8 x int32
int vec_end = (n / vec_width) * vec_width; // = 512
// Vektorisierte Hauptschleife (0..511)
for (int i = 0; i < vec_end; i += vec_width) {
__m256i a_v = _mm256_loadu_si256((__m256i*)&a[i]);
__m256i b_v = _mm256_loadu_si256((__m256i*)&b[i]);
_mm256_storeu_si256((__m256i*)&c[i], _mm256_add_epi32(a_v, b_v));
}
// Skalarer Tail (512..512, also genau 1 Element)
for (int i = vec_end; i < n; i++) {
c[i] = a[i] + b[i];
}Strategie 2: Array auffüllen (Padding)
Man allokiert das Array auf das nächste Vielfaches der Vektorbreite aufgerundet und füllt die überschüssigen Elemente mit neutralen Werten (z.B. 0). Dann kann die Hauptschleife ohne Sonderfall über das gesamte Array laufen:
int n_padded = ((n + vec_width - 1) / vec_width) * vec_width; // = 520
int *a = aligned_alloc(32, n_padded * sizeof(int));
memset(a + n, 0, (n_padded - n) * sizeof(int)); // Pad mit 0Strategie 3: Maskierte Loads/Stores (AVX-512)
AVX-512 erlaubt es, einen Vektor zu laden und dabei nur bestimmte Lanes zu aktivieren. Die Maske ergibt sich direkt aus der Restlänge:
int tail = n % 16; // AVX-512: 16 x int32
__mmask16 mask = (1 << tail) - 1; // Bitmask für die tail Lanes
__m512i a_v = _mm512_maskz_loadu_epi32(mask, &a[vec_end]);
__m512i b_v = _mm512_maskz_loadu_epi32(mask, &b[vec_end]);
_mm512_mask_storeu_epi32(&c[vec_end], mask, _mm512_add_epi32(a_v, b_v));Dies ist die eleganteste Lösung, erfordert aber AVX-512-Hardware.
Übungsaufgabe: Gegeben sei ein Array float a[N] mit beliebigem N. Implementieren Sie eine Funktion float sum(float *a, int n), die alle Elemente mit AVX2 (8 Floats) aufsummiert und den Rest skalär behandelt.
Bedingte Ausführung: Maskierung¶
Da SIMD-Befehle immer auf das ganze Register wirken, können if-Bedingungen nicht einfach übersprungen werden. Die Lösung sind Masken-Register (in AVX-512 die Register k0 bis k7).
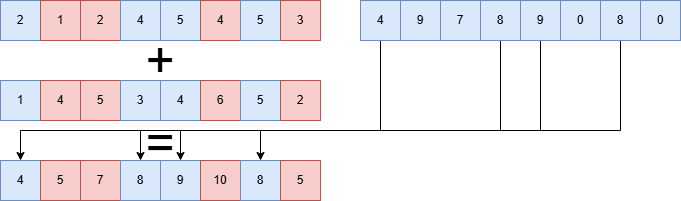
Figure 7:mask_add_ps: Die maskierten Werte werden aus einem Quellvekotr entnommen
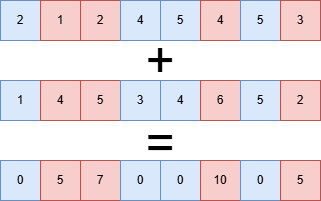
Figure 8:mask_addz_ps: Die maskierten Werte werden auf Null gesetzt.
Funktionsweise:¶
Vergleich: Ein Befehl wie
_mm512_cmp_ps_maskvergleicht zwei Vektoren und gibt eine Bitmaske zurück (z. B. eine__mmask16).Maskierte Operation:
_mm512_mask_add_ps: Berechnet das Ergebnis nur dort, wo die Maske1ist. Wo sie0ist, wird der Wert aus einem Quell-Vektor übernommen._mm512_maskz_add_ps: (“z” für zeroing) Wo die Maske0ist, wird das Ergebnis im Ziel-Vektor auf Null gesetzt.
Beispiel:
void if_s(double *x, int n, double c1, double c2) {
for (int i = 0; i < n; i++){
if(x[i]>1.0)
x[i]= c1*x[i];
else
x[i] = c2*x[i]; }
}
kann so umgesetzt werden:
void mm512_if_s(double *x, int n, double c1, double c2) {
__m512d vx;
__m512d vc1 = _mm512_set1_pd(c1);
__m512d vc2 = _mm512_set1_pd(c2);
__m512d ones = _mm512_set1_pd(1.0);
for (int i = 0; i < n; i+=8){
vx = _mm512_loadu_pd(x+i);
__mmask8 mask = _mm512_cmp_pd_mask(vx,ones, _CMP_GT_OQ) ;
vx = _mm512_mask_mul_pd(vx, mask, vc1,vx);
mask = mm512_kxor(mask,(__mmask8)0xffff);
vx = _mm512_mask_mul_pd(vx, mask, vc2,vx);
_mm512_storeu_pd(x+i, vx);
}
}10. OpenMP SIMD: Fortgeschrittene Konzepte¶
OpenMP ist oft der bessere Weg, da es portabel bleibt. Man sollte jedoch ein paar Dinge beachten, wenn man es zusammen mit OpenMP threads verwendet.
Kombinierte Parallelisierung¶
Häufig sieht man:
#pragma omp parallel for simdWichtig für das Verständnis: Die Iterationen werden erst auf die verschiedenen CPU-Kerne (Threads) verteilt und danach innerhalb jedes Threads per SIMD vektorisiert.
Das Scheduling-Problem¶
In den Folien wird davor gewarnt, ein zu kleines oder unpassendes Chunk-Size zu wählen:
Schlecht:
schedule(static, 5)bei einem Vektor-Register, das 8 Elemente fasst. Das führt dazu, dass die Vektoreinheit nicht effizient gefüllt werden kann.Besser:
schedule(simd:static, chunk_size). Das Schlüsselwortsimdsignalisiert dem Scheduler, dass die Chunk-Größe ein Vielfaches der SIMD-Breite sein sollte.
Safelen und Abhängigkeiten¶
Wenn der Compiler eine Abhängigkeit vermutet, die wir als Programmierer ausschließen können:
safelen(n): Gibt an, dass keine Abhängigkeiten zwischen Iterationen existieren, die weniger alsnSchritte auseinanderliegen. Der Compiler darf dann Vektoren mit bis zunElementen erzeugen — aber keinen breiteren Vektor, da sonst Korrektheit nicht garantiert wäre.
11. Fazit und Alternativen¶
Neben Intrinsics und OpenMP gibt es moderne C++ Bibliotheken, die SIMD-Abstraktionen bieten (z. B. std::simd (experimental), Google Highway oder Vc). In der Praxis nutzen fast alle performanten Mathe-Bibliotheken (BLAS, Intel MKL) intern diese SIMD-Techniken.
Zusammenfassend:
Auto-Vektorisierung: Erster Schritt, Flags nutzen (
-O3,-march=native).OpenMP SIMD: Wenn der Compiler Hilfe braucht oder Parallelisierung kombiniert werden soll.
Intrinsics: Wenn jedes Quäntchen Performance zählt und Portabilität zweitrangig ist.