Kurseinheit 3: OpenMP Tasks
1. Einführung: Warum Tasks?¶
Klassisches OpenMP¶
Das klassische OpenMP behandelt Threads als fundamentales Konzept:
Man weiß, wie viele Threads es gibt (
omp_get_num_threads()).Man weiß, welcher Thread gerade läuft (
omp_get_thread_num()).Arbeitsteilung erfolgt explizit via
schedule-Klausel oderomp_get_thread_num()-Abfragen.
Vor OpenMP 3.0 war die Parallelisierung auf Schleifen (#pragma omp for) und Sektionen (#pragma omp sections) beschränkt. Dies stieß bei unregelmäßigen Problemen an Grenzen:
Rekursion: (z. B. Quicksort, Fibonacci), bei denen die Arbeitslast dynamisch entsteht.
While-Schleifen: Bei denen die Anzahl der Durchläufe vorab unbekannt ist (z. B. Durchlaufen verketteter Listen).
Unregelmäßige Datenstrukturen: Bäume oder Graphen.
Das Task-Paradigma¶
Für Tasks muss man das klassische Denken loslassen:
Vergiss Threads und wie man Arbeit am besten zwischen ihnen aufteilt.
Stattdessen: Wie teile ich meinen Code in Stücke auf, die unabhängig voneinander ausgeführt werden können?
Abhängigkeiten zwischen Tasks sind dabei explizit ausdrückbar.
Die OpenMP-Laufzeit sorgt dann dafür, dass Tasks von Threads ausgeführt werden.
Das Task-Konzept: Ein Task ist eine abgeschlossene Arbeitseinheit (Code + Daten), die in einen Pool gegeben und von einem beliebigen verfügbaren Thread des Teams ausgeführt wird. Die Ideen stammen aus Cilk; ähnliche Konzepte gibt es in TBB.
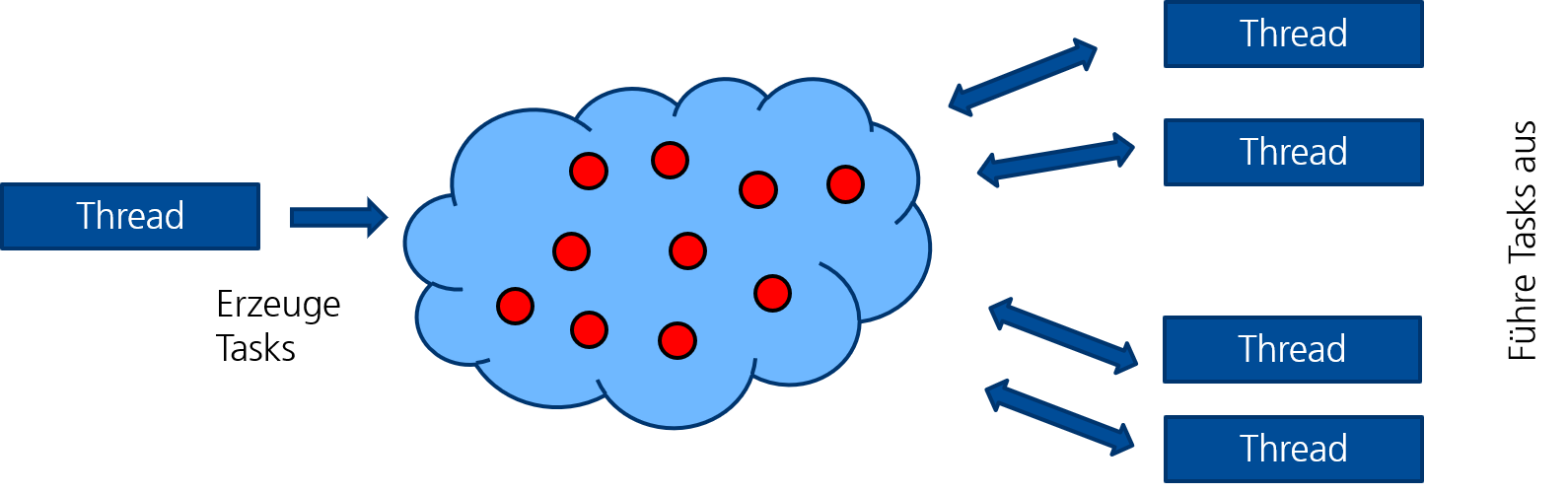
Figure 1:Task-Pool in OpenMP (und anderen Task-Programmiermodellen)
2. Ausführungsmodell¶
Wenn der Compiler eine #pragma omp task-Direktive entdeckt, wird ein Task-Objekt erzeugt (Code + Datenkopien). Wann dieser Task ausgeführt wird, entscheidet allein die Laufzeit:
Er kann sofort vom erzeugenden Thread ausgeführt werden.
Er kann verzögert in einen Pool gelegt und später von einem beliebigen Thread abgearbeitet werden.
Threads, die an einer Barriere ankommen und keine Schleifenarbeit mehr haben, beginnen automatisch, Tasks aus dem Pool abzuarbeiten – sie idlen nicht. Nur bestimmte Konstrukte zwingen zur Synchronisation (→ Abschnitt 6).
3. Syntax und Grundlagen¶
Ein Task wird mit der Direktive #pragma omp task definiert.
Der Single-Start¶
Meistens soll nur ein Thread Tasks erzeugen, während die anderen Threads bereitstehen, um diese abzuarbeiten:
#pragma omp parallel
{
#pragma omp single
{
#pragma omp task
do_work_a();
#pragma omp task
do_work_b();
}
// implizite Barriere: alle Threads warten, bis single-Block fertig ist
}nowait auf single¶
Standardmäßig haben alle anderen Threads nach dem single-Block eine implizite Barriere – sie warten, bis der eine Thread den Block abgeschlossen hat. Mit nowait entfällt diese Barriere: die anderen Threads beginnen sofort, erzeugte Tasks abzuarbeiten, während der single-Thread noch läuft. Das ist besonders nützlich, wenn Tasks erzeugt werden sollen, bevor die Erzeugungs-Schleife fertig ist:
#pragma omp single nowait // andere Threads warten NICHT
while (p) {
#pragma omp task firstprivate(p)
{ processwork(p); }
p = p->next;
}taskwait – Synchronisation¶
Mit #pragma omp taskwait wartet der erzeugende Thread auf den Abschluss aller bisher erzeugten Kind-Tasks:
#pragma omp parallel
{
#pragma omp single
{
printf("A ");
#pragma omp task
{ printf("car "); }
#pragma omp task
{ printf("race "); }
#pragma omp taskwait
// Erst hier ist garantiert: "car" und "race" wurden ausgegeben
printf("is fun to watch");
}
}
// Mögliche Ausgaben: "A car race is fun to watch" oder "A race car is fun to watch"Ohne taskwait ist die Reihenfolge nicht definiert – Threads, die an der impliziten Barriere am Ende der parallel-Region idlen, beginnen dort, Tasks abzuarbeiten, was zu beliebiger Verschachtelung führt.
4. Variablen-Gültigkeit (Data Environment)¶
Tasks können verzögert ausgeführt werden – die erzeugenden Variablen können zu dem Zeitpunkt längst out-of-scope sein. Daher gelten eigene Scoping-Regeln:
firstprivate(Standard für die meisten Variablen): Der Task erhält zum Zeitpunkt der Erzeugung eine Kopie. Änderungen wirken sich nicht auf das Original aus.shared(Standard für global/heap-shared Variablen): Der Task greift auf die Originalvariable zu. Erfordert Vorsicht bzgl. Lebensdauer (Stack!) und expliziter Synchronisation.
Präzise Scoping-Regel:
Variablen, die im einschließenden Parallel-Konstrukt
privateoderfirstprivatesind → im Taskfirstprivate.Variablen, die in allen Konstrukten ab dem innersten
parallelsharedsind → im Taskshared.Im Task neu deklarierte Variablen →
private.
int a = 1; // global
void foo() {
int b = 2, c = 3;
#pragma omp parallel private(b) // b ist private, a und c sind shared
{
int d = 4;
#pragma omp single
{
#pragma omp task
{
int e = 5;
// a: shared (Wert: 1)
// b: firstprivate (Wert: 0 / uninitialisiert, da im parallel private)
// c: shared (Wert: 3)
// d: firstprivate (Wert: 4, da d im parallel lokal ist)
// e: private (Wert: 5)
compute(a, b, c, d, e);
}
}
}
}Best Practice: default(none) verwenden, um Scoping-Fehler zur Compilezeit zu erkennen.
5. Praxisbeispiel: Verkettete Liste¶
Eine verkettete Liste ist mit klassischem OpenMP schwer zu parallelisieren, da die Länge zur Compilezeit unbekannt ist. Die aufwändige Lösung erfordert erst das Zählen, Kopieren in ein Array und dann einen parallel for. Mit Tasks geht es direkt:
int result = 0, errors = 0;
p = head;
#pragma omp parallel firstprivate(p) shared(result, errors)
{
#pragma omp single nowait
while (p) {
#pragma omp task firstprivate(p) shared(result, errors)
{
int temp = processwork(p);
if (temp >= 0) {
#pragma omp atomic update
result += temp;
}
}
p = p->next;
}
}Die processwork-Funktion muss bei konkurrierenden Schreibzugriffen auf errors gesichert werden:
int processwork(struct element* p) {
if (p->value <= 0) {
#pragma omp critical
{ errors += 1; }
return -1;
}
return 10 / (p->value);
}Hinweis: Tasks nicht für Dinge einsetzen, die OpenMP bereits effizient unterstützt (z. B. reguläre
for-Schleifen). Der Task-Overhead ist höher als beim einfachenparallel for.
6. Effizienz und Optimierung (Fibonacci-Fallstudie)¶
Schauen wir uns nun ein etwas ausführlicheres Beispiel an, das Sie bereits aus der letzten Kurseinheit kennen. Die Berechnung der Fibonacci-Zahlen mittels Rekursion. Naiv würde man das Ganze wie unten dargestellt mit Tasks parallelisieren.
Hinweis: Eine solche Aufgabe mit Threads zu parallelisieren, ist eine sehr schlechte Idee, da das Erzeugen neuer Threads sehr aufwendig ist. Innerhalb einer Rekursion würden Threads rekursiv immer neue Threads erzeugen, was sehr schnell zu einer unkontrollierten Anzahl an Threads führt.
Naive Implementierung¶
int fib(int n) {
if (n < 2) return n;
int x, y;
#pragma omp task shared(x) firstprivate(n)
{ x = fib(n - 1); }
#pragma omp task shared(y) firstprivate(n)
{ y = fib(n - 2); }
#pragma omp taskwait
return x + y;
}Problem: Bei großem n entstehen exponentiell viele Tasks. Der Verwaltungs-Overhead überwiegt die Rechenzeit bei Weitem – die parallele Version ist langsamer als die serielle.
Optimierung 1: Die if-Klausel (Cut-off Strategie)¶
Wenn die if-Bedingung false ist, wird kein Task erzeugt, sondern der Code sofort im aktuellen Thread ausgeführt:
int fib(int n) {
if (n < 2) return n;
int x, y;
#pragma omp task shared(x) firstprivate(n) if(n > 30)
{ x = fib(n - 1); }
#pragma omp task shared(y) firstprivate(n) if(n > 30)
{ y = fib(n - 2); }
#pragma omp taskwait
return x + y;
}Effekt: Die „schweren" Aufgaben oben im Rekursionsbaum laufen parallel, die „kleinen" Aufgaben unten laufen ohne Task-Overhead sequentiell.
Ergebnis: Deutlich besser als die naive Version, aber oft noch schlechter als die serielle.
Optimierung 2: Expliziter serieller Cut-off (empfohlen)¶
int serialfib(int n) {
if (n < 2) return n;
return serialfib(n - 1) + serialfib(n - 2);
}
int fib(int n) {
if (n < 30) return serialfib(n); // unter Schwellwert: direkt seriell
int x, y;
#pragma omp task shared(x)
{ x = fib(n - 1); }
#pragma omp task shared(y)
{ y = fib(n - 2); }
#pragma omp taskwait
return x + y;
}Durch den expliziten Wechsel auf eine serielle Funktion entfällt der Task-Overhead vollständig für das untere Drittel des Rekursionsbaums.
7. Scheduling und Task Scheduling Points (TSP)¶
OpenMP Tasks werden intern durch Random Work Stealing nach Blumofe verteilt (Details → Tasks.md, Abschnitt 5). Aus Sicht des OpenMP-Programmierers ist das Wichtigste: Der Wechsel zwischen Tasks findet nur an definierten Task Scheduling Points statt:
#pragma omp task(Task-Erzeugung)#pragma omp taskwait#pragma omp barrier(explizit oder implizit am Ende vonparallel,single,for)
Zwischen diesen Punkten läuft ein Task unterbrechungsfrei auf seinem Thread durch. Das verhindert willkürliche Unterbrechungen und macht das Verhalten vorhersagbar.
Das #pragma omp taskyield Konstrukt¶
Definition und Zweck Die
taskyield-Direktive ist ein expliziter Task Scheduling Point (TSP). Sie dient als Hinweis (Hint) an das OpenMP-Laufzeitsystem, dass der aktuell ausführende Task an dieser Stelle unterbrochen werden kann, um anderen Tasks den Vorrang zu lassen.Funktionsweise In einem System mit Work-Stealing kann es vorkommen, dass ein Thread einen sehr lang laufenden Task bearbeitet, während andere Threads bereits leerlaufend sind oder sich in der Queue wichtige, kurze Tasks stauen. Ohne
taskyieldwürde der Thread den langen Task bis zum nächsten impliziten TSP (z. B.taskwait) starr durchziehen.
Mit taskyield signalisiert der Programmierer:
„Ich befinde mich gerade an einer unkritischen Stelle. Wenn andere Tasks warten, unterbrich mich kurz, lass die anderen arbeiten und kehre später zu mir zurück.“
Wann ist Task-Yield sinnvoll? Der Einsatz ist vor allem in zwei Szenarien wertvoll:
Verhindern von Verhungern (Starvation): In einer Schleife, die viele kleine Tasks erzeugt, kann ein taskyield sicherstellen, dass das System Zeit findet, die erzeugten Tasks auch tatsächlich abzuarbeiten, statt nur neue zu generieren.
Warten auf Ressourcen: Wenn ein Task auf eine Ressource wartet (z. B. eine Sperre oder Daten), die noch nicht bereit ist, ist ein taskyield effizienter als aktives Warten (Spin-Wait), da der Thread in der Zwischenzeit andere nützliche Arbeit leisten kann.
Wichtige Verhaltensregeln Nur ein Hinweis: Das Laufzeitsystem ist nicht verpflichtet, den Task zu unterbrechen. Wenn keine anderen Tasks warten, läuft der Task einfach ohne Verzögerung weiter.
Thread-Zugehörigkeit: Bei untied-Tasks kann der Task nach einem taskyield auf einem anderen Thread fortgesetzt werden. Standard-Tasks sind tied und werden stets auf demselben Thread fortgesetzt.
Seiteneffekte: Da taskyield ein TSP ist, können sich geteilte Variablen (Shared Memory) zwischen dem Aufruf und der Fortführung des Tasks geändert haben, da in der Zwischenzeit andere Tasks auf demselben Thread gelaufen sein könnten.
#pragma omp task
{
for (int i = 0; i < 1000; i++) {
do_heavy_computation(i);
// Erlaube dem Scheduler, andere wichtige Tasks
// dazwischenzuschieben, falls das System ausgelastet ist.
#pragma omp taskyield
}
}8. Divide and Conquer mit Tasks¶
Divide and Conquer ist ein wichtiges Entwurfsmuster mit zwei Phasen:
Divide (Teilen): Zerlegung des Problems in zwei oder mehr Teilprobleme desselben Typs, bis diese direkt lösbar sind.
Conquer (Zusammenführen): Lösung der atomaren Teilprobleme und Kombination der Teillösungen zur Gesamtlösung.
Die Umsetzung erfolgt typischerweise rekursiv. Tasks sind ideal dafür, da die Rekursionsstruktur direkt auf die Task-Erzeugung abgebildet wird und kein nested parallelism (Threads erzeugen Threads) nötig ist.
Quicksort mit Tasks¶
Algorithmus:
Divide: Wähle ein Pivot-Element; partitioniere das Array so, dass alle kleineren Elemente links und alle größeren rechts des Pivots landen.
Conquer: Sortiere rekursiv die linke und rechte Teilhälfte (sind unabhängig voneinander → parallelisierbar).
Worst-case: O(n²), durchschnittlich: O(n log n).
Naive Task-Implementierung:
void quick_sort(int p, int r, int *data) {
if (p < r) {
int q = partitionArray(data, p, r);
#pragma omp task default(none) shared(data) firstprivate(p, q, r)
{ quick_sort(p, q - 1, data); }
#pragma omp task default(none) shared(data) firstprivate(p, q, r)
{ quick_sort(q + 1, r, data); }
}
}Optimierte Version mit seriellem Cut-off:
void quick_sort(int p, int r, int *data, int low_limit) {
if (p < r) {
if ((r - p) < low_limit) {
seq_quick_sort(p, r, data); // unter Schwellwert: seriell
} else {
int q = partition(p, r, data);
#pragma omp task firstprivate(data, low_limit, r, q, p)
quick_sort(p, q - 1, data, low_limit);
#pragma omp task firstprivate(data, low_limit, r, q, p)
quick_sort(q + 1, r, data, low_limit);
}
}
}Wie bei Fibonacci: kleine Teilprobleme direkt seriell lösen, um Task-Overhead zu vermeiden.
9. Task-Abhängigkeiten (Task Dependencies)¶
Anstatt mit #pragma omp taskwait auf alle Kind-Tasks zu warten, erlaubt die depend-Klausel feingranulare Steuerung des Datenflusses.
Syntax¶
#pragma omp task depend(dependency-type: list)Abhängigkeitstypen¶
depend(out: var): Der Task schreibtvar. Alle nachfolgenden Tasks, dievarin einerin-,out- oderinout-Klausel referenzieren, müssen warten.depend(in: var): Der Task liestvar. Er wartet auf alle vorherigen Geschwister-Tasks, dievarin einerout- oderinout-Klausel referenzieren.depend(inout: var): Der Task liest und schreibtvar– Kombination aus beiden.
Die list-Elemente können auch Array-Abschnitte enthalten (z. B. A[i][j]).
Vorteil: Das System baut automatisch einen Abhängigkeitsgraphen (DAG) auf. Tasks können ausgeführt werden, sobald ihre spezifischen Daten bereit sind – auch wenn andere Tasks noch laufen.
Beispiel: Abhängige Tasks in einer Schleife¶
Version 1 – single mit depend:
void process_in_parallel() {
#pragma omp parallel
#pragma omp single
{
int x = 1;
for (int i = 0; i < T; ++i) {
#pragma omp task shared(x) depend(out: x) // T1
preprocess_some_data(...);
#pragma omp task shared(x) depend(in: x) // T2
do_something_with_data(...);
#pragma omp task shared(x) depend(in: x) // T3
do_something_independent_with_data(...);
}
}
}T1 muss beendet sein, bevor T2 und T3 starten.
T2 und T3 können parallel laufen (beide nur
in).Einschränkung: Die Abhängigkeit über
xkoppelt die Iterationen – Iterationi+1muss auf Iterationiwarten.
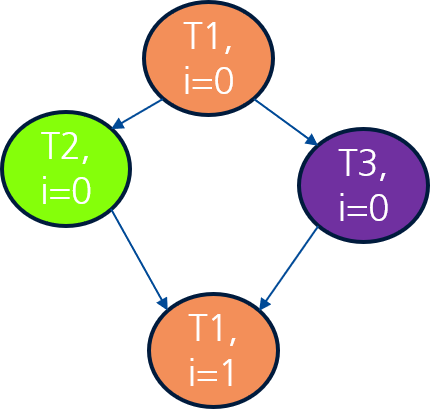
Figure 2:Task-Graph für das Beispiel 1
Version 2 – parallel for mit depend:
#pragma omp for
for (int i = 0; i < T; ++i) { // i ist privat pro Thread
#pragma omp task depend(out: i) // T1
preprocess_some_data(...);
#pragma omp task depend(in: i) // T2
do_something_with_data(...);
#pragma omp task depend(in: i) // T3
do_something_independent_with_data(...);
}Da
iprivat ist, sind die Iterationen unabhängig → mehr Parallelität möglich.
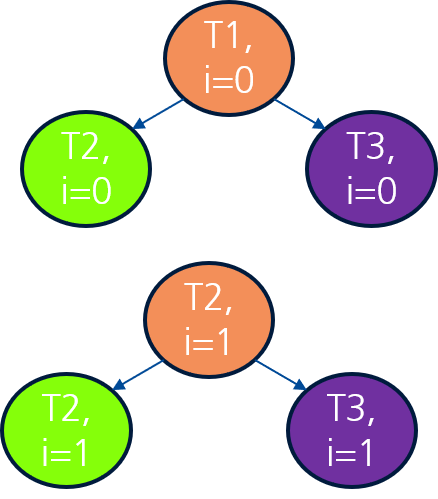
Figure 3:Task-Graph für das Beispiel 2
Version 3 – äußerer Task pro Iteration (maximale Parallelität):
#pragma omp single
for (int i = 0; i < T; ++i) {
#pragma omp task firstprivate(i)
{
#pragma omp task depend(out: i) // T1
preprocess_some_data(...);
#pragma omp task depend(in: i) // T2
do_something_with_data(...);
#pragma omp task depend(in: i) // T3
do_something_independent_with_data(...);
}
}Alle Iterationen können vollständig überlappen – maximale Auslastung des kritischen Pfades.
10. Komplexes Beispiel: Blockweise LU-Zerlegung¶
Die LU-Zerlegung (Gauss-Elimination) zerlegt eine Matrix A in eine untere Dreiecksmatrix L und eine obere Dreiecksmatrix U. Der serielle Algorithmus:
for (int i = 0; i < size; i++) {
for (int j = i + 1; j < size; j++) {
A[j][i] /= A[i][i]; // Spalten-Division
for (int k = i + 1; k < size; k++) {
A[j][k] -= A[j][i] * A[i][k]; // Zeilenupdate
}
}
}Blockweise Zerlegung¶
Für große Matrizen unterteilt man in Blöcke und definiert vier Operationen:
| Operation | Beschreibung | Abhängigkeit |
|---|---|---|
diag_op | LU auf dem Diagonalblock | nur von sich selbst (inout) |
row_op | Update der Blöcke in derselben Zeile | von diag_op (in) |
col_op | Update der Blöcke in derselben Spalte | von diag_op (in) |
inner_op | Update der inneren Blöcke | von row_op und col_op (in) |
Implementierung mit depend¶
for (int i = 0; i < num_blocks; i++) {
#pragma omp task depend(inout: block_list[i][i])
diag_op(block_list[i][i]);
for (int j = i + 1; j < num_blocks; j++) {
#pragma omp task depend(in: block_list[i][i]) depend(inout: block_list[i][j])
row_op(block_list[i][j], block_list[i][i]);
#pragma omp task depend(in: block_list[i][i]) depend(inout: block_list[j][i])
col_op(block_list[j][i], block_list[i][i]);
}
for (int j = i + 1; j < num_blocks; j++) {
for (int k = i + 1; k < num_blocks; k++) {
#pragma omp task depend(in: block_list[i][k], block_list[j][i]) \
depend(inout: block_list[j][k])
inner_op(block_list[j][k], block_list[i][k], block_list[j][i]);
}
}
}
#pragma omp taskwaitDas System baut automatisch den korrekten DAG auf: row_op und col_op können parallel nach diag_op starten; inner_op startet, sobald seine spezifischen row_op- und col_op-Tasks fertig sind – ohne globale Barrieren.
11. Zusammenfassung und Best Practices¶
| Thema | Empfehlung |
|---|---|
| Granularität | Tasks groß genug wählen, um Erzeugungsoverhead zu rechtfertigen; if-Klausel oder expliziten seriellen Cut-off verwenden. |
| Synchronisation | depend gegenüber taskwait bevorzugen für bessere Parallelauslastung. |
| Daten-Scope | firstprivate für lokale Werte; Vorsicht mit shared-Zeigern auf den Stack der Elternfunktion. |
| Scoping-Sicherheit | default(none) verwenden, um Scoping-Fehler frühzeitig zu erkennen. |
| Anwendungsbereich | Tasks nicht für Probleme einsetzen, die OpenMP bereits gut unterstützt (z. B. reguläre for-Schleifen). |
| Rekursion | Nested Parallelism (Threads erzeugen Threads) vermeiden; stattdessen Tasks verwenden. |